Types of Numbers
Positive Integers
N = {0, 1, 2, 3, ...}
Integers
Z = {..., -3, -2, -1, 0, 1, 2, 3, ...}
Rationals
![]()
Irrationals
Numbers not in the sets of rationals or integers, e.g., ![]()
Reals
R - union of the sets of rationals and irrationals
The set of reals is infinite and uncountable.
The set of integers and rationals are infinite and countable.
![]()
Intervals on sets of reals
- Closed interval:
![[a,b]={x|a<=x<=b} c R](mcsimg/closedinterval.gif)
- Open interval:
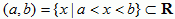
Therefore, we can write the set of reals as: ![]()
We can also mix intervals to get half-opened intervals, e.g.: ![]() or
or ![]() .
.
Functions
Informal definition
f : A -> B
Function f maps every value from domain A onto a single value in the range B.
Formal definition
![]()
Image of the Function
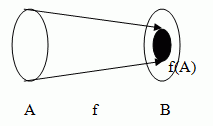
If f(A) = B, then the function is surjective and can be inverted.
The image is that portion of the range for which there exists a mapping for the domain.
Combining Functions

Classes of Function
Injective Function
One-to-one mapping from domain to range.
![]()
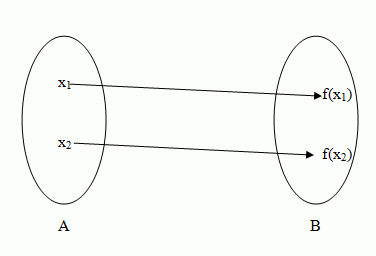
The above diagram shows an injective function, however the one below does not show an injective function.
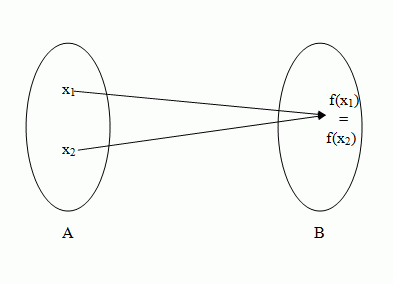
Surjective Function
Every value in the range is mapped onto from the domain, the image is identical to the range.
![]()
Something that is both injective and surjective is bijective.
Properties of Functions
A function is even if ![]()
A function is odd if ![]()
Special Types of Functions
- Polynomial function of degree x.
- Rational functions (
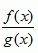 ) where f(x) and g(x) are polynomials.
) where f(x) and g(x) are polynomials. - Algebraic functions (sum, difference, quotient, power or product of rationals)
Piecewise Function
Function is built up over a series of intervals, e.g.,:
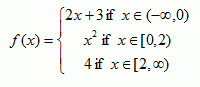
A more general case could be:
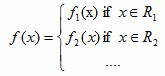
The domain of f(x) is the union of the intervals R1, R2, etc: ![]() .
.
To ensure that the piecewise function is indeed a function, they must be pairwise disjoint: ![]() . If any intervals overlap, it is not pairwise disjoint, and is not a function.
. If any intervals overlap, it is not pairwise disjoint, and is not a function.
Function Inverse
Let f : A -> B be an injective function. The function g : B -> A is the inverse of f if: ![]() . g(y) can also be written as f-1(y).
. g(y) can also be written as f-1(y).
A function is not invertable if it is not injective or not surjective.
Function Composition
Consider 2 functions - f : B -> C and g : A -> B, where the domain at f must be indentical to the image of g.
(f·g)(x) = f(g(x))
f·g has domain A and range C. g must be surjective otherwise f is not a function.
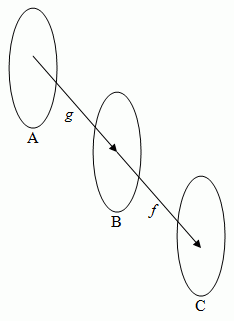
g(A) = B
Function Limits
- As x gets closer and closer to a, does the value of function f(x) get closer and closer to some limit, L?
- Can we make the function value f(x) as close to L as desired by making x sufficiently close to a?
If both of the above requirements are met, then: ![]()
A more formal definition is: ![]()
Limit Rules
- Constant:
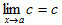
- Linear:
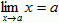
- Power rule:
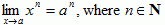
- Functions to powers:
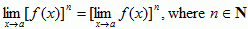
- Linear roots:
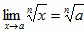 , if a > 0 and n is a positive integer, or a < 0 and n is an odd positive integer
, if a > 0 and n is a positive integer, or a < 0 and n is an odd positive integer - Roots of functions:
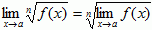 , if n is an odd positive integer, or n is an even positive integer and
, if n is an odd positive integer, or n is an even positive integer and 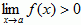
- If p(x) is a polynomial function of x and a
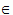 R, then
R, then 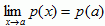
- If q : A -> B is a rational function with A, B
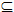 R and if a A, then provided that q(a) exists
R and if a A, then provided that q(a) exists 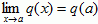
Compound Functions Rules
- Constant multiplier:
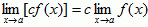
- Sum:
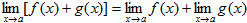
- Difference:
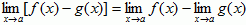
- Product:
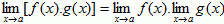
- Quotient:
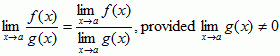
Tolerances
x has tolerance δ if x (a - δ, a + δ). f(x) has tolerance ε if f(x) (L - ε, L + ε).
Infinite Limits
The statement ![]() means that for every ε > 0 there exists a number M such that if x > M then |f(x) - L| < ε. On a graph, this is represented as the function f(x) lying between the horizontal lines y = L ± ε. The line y = L is called the horizontal asymptote of the graph of x.
means that for every ε > 0 there exists a number M such that if x > M then |f(x) - L| < ε. On a graph, this is represented as the function f(x) lying between the horizontal lines y = L ± ε. The line y = L is called the horizontal asymptote of the graph of x.
Continuity of a Function
A function is continuous if its graph has:
- no breaks
- no holes
- no vertical asymptotes
Therefore, we can say that there are the following types of discontinuity:
- removable discontinuity
- jump discontinuity (piecewise functions)
- infinite discontinuity (vertical asymptote)
Conditions for Continuity
f : A -> B is continuous at c A if:
- f(c) B and
-
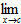 f(c) exists and
f(c) exists and - f(x) = f(c)
For special functions
- Polynomial p(x) (p : R -> R) is continuous for every real number x R.
- A rational function q(x) = is continuous at every real number x R, except where g(x) = 0.
Continuity on an Interval
Let function f : A -> B be defined on the open interval (a,b) ![]() A
A ![]() R. The function is said to be continuous on (a, b) if:
R. The function is said to be continuous on (a, b) if:
- f(x) exists for all c (a, b)
- f(x) = f(c)
![]()
If we want the function to be defined on the closed interval [a,b], then we must tighten up the above definition to include:
- f(a) and f(b) are defined
-
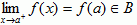
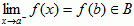
Continuity of Compound Functions
If f and g are continuous, then so are:
- the sum
- the difference
- the product
- the quotient (provided that g(x) ≠ 0)
Continuity of Composite Functions
Consider: f : B -> C and g : A -> B (this is surjective). The domain of f must be identical to the image of g.
Consider the composition f ∧ g, if ![]() g(x) = b and f is continuous at b, then
g(x) = b and f is continuous at b, then ![]() f(g(x)) = f(b) = f(
f(g(x)) = f(b) = f(![]() g(x)). If, in addition, g is continuous at c and f is continuous at g(c), then
g(x)). If, in addition, g is continuous at c and f is continuous at g(c), then ![]() f(g(x)) = f(b) = f(
f(g(x)) = f(b) = f(![]() g(x)) = f(g(c)), then the composite function f ∧ g is continuous at c.
g(x)) = f(g(c)), then the composite function f ∧ g is continuous at c.
Intermediate Value Theorem
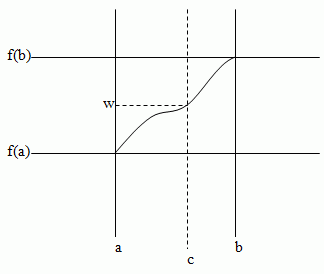
If f is continuous on [a, b] and w [min(f(a), f(b)), max(f(a), f(b))], then there exists at least one number in [a, b] such that f(c) = w.
f(w) [f(a), f(b)] => ∃≥1c [a, b][f(c) = w]
Zeroes of a Function
A function f : A -> B is said to have 0 at r ![]() A if f(r) = 0
A if f(r) = 0
Calculus
Derivative of a continuous function
Provided the limit exists: ![]() . Therefore, we can consider the derivative as a function. The domain is the union of all intervals over which f′ exists. f is differentiatible if ∃f′(x).∀x
. Therefore, we can consider the derivative as a function. The domain is the union of all intervals over which f′ exists. f is differentiatible if ∃f′(x).∀x ![]() (a, b). Over the closed interval [a, b], f is differentiatible if:
(a, b). Over the closed interval [a, b], f is differentiatible if:
- it is differentiatible over the open interval (a, b) and
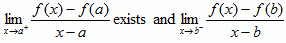 exists
exists
Derivative of an Inverse Function
Let g be the inverse of function f : A -> B.
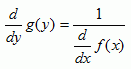 provided that
provided that ![]() ≠ 0.
≠ 0.
However, this is not well formed, as y is expressed in terms of x. We must use our knowledge of the original formula and derivative to reform the derivative to be all in terms of y.
Derivative of composite functions
![]() f(g(x)) =
f(g(x)) = ![]() f∧g(x)
f∧g(x)
We can use the chain rule to differentiate this. The chain rule is ![]() f(g(x)) = f′(x).g′(x).
f(g(x)) = f′(x).g′(x).
The Exponential
The exponential function is of the form ax, where a ∈ (0,∞) and it is a positive real number constant. The exponential function is defined in five stages.
- If x is a positive integer then ax = a × a × a ... x times.
- If x = 0, then a0 = 1
- If x = -n, where n is a positive integer, then a-n = 1/an
- If x =
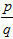 , where this is a rational number (i.e., p, q ∈ Z), then
, where this is a rational number (i.e., p, q ∈ Z), then 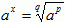
- If x ∈ R, then
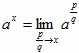
If a ∈ (0,∞), then ax is a continuous function with domain R and range (0,∞).
It is important to remember that this is not the same as the polynomial function. In a polynomial, the function varies on the base, but here it varies on the exponent. f(x) = ax is exponential, but f(x) = xn is polynomial.
Monotonicity
- If a ∈ (0,1) then ax is a decreasing function.
- If a ∈ (1,∞)then ax is an increasing function.
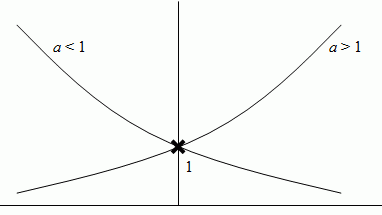
Exponentials can also be combined. If a, b ∈ (0, ∞) and x, y ∈ R, then ax + y = ax × ay and ax - y = ax ÷ ay. Also, (ax)y = axy and (ab)x = axbx
Exponential Limits
- If a > 1, limx → ∞ ax = ∞ and limx → -∞ ax = 0
- If a < 1 limx → ∞ ax = 0 and limx → -∞ ax = ∞
Derivative of Exponential
If we try to derive from first principles, we get an indeterminate number in the form of 0/0, so the limit is when x = 0. Hence, we can say that f′(x) = f′(0)ax
Natural Exponential
This is the exponential where f′(0) = 1, we call this number e and f′(x), where f(x) = ex, is ex - it is equal everywhere to its own derivative.
Natural Logarithm
The inverse of the natural exponential is the natural logarithm. y = ex ⇔ x = ln y
In order to satisfy injectivity, the domain is (0, ∞) and the range is R.
To figure out the derivative of the natural logarithm, we can use the rules we already know about inverses to get Dy ln y = 1/ex. To get things in terms of y, if we sub y = ex in we get Dy ln y = 1/y
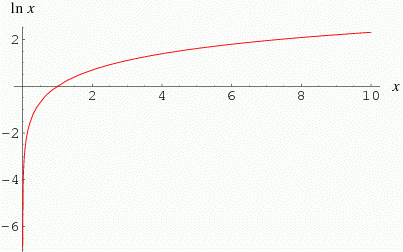
The natural logarithm takes the normal logarithmic rules.
Say you want to express ax as an exponential to base e.
ax = ef(x) and then you can take natural logarithms of both side to get x ln a = f(x), therefore by substituting back in, ax = ex ln a.
This can then be used to differentiate ax
Dx ax = Dx ex ln a = ln a ex ln a, which by substituting back in becomes ln a ax.
By differentiating from first principles, we showed Dx ax = ax ![]() , but since we now know that Dx ax = ax ln a, then ax ln a = ax
, but since we now know that Dx ax = ax ln a, then ax ln a = ax ![]() . We can cancel through by ax and get ln a =
. We can cancel through by ax and get ln a = ![]() , so we can now say that f′(x) = ax ln a
, so we can now say that f′(x) = ax ln a
Using the rules we learnt earlier for inverses, we can derive the derivative for logax, which gives us Dy logay = 1/(y ln a)
Iteration Algorithms
Consider xr + 1 = (xr2 + 3) / 4. This has fixed points at 1 and 3. A fixed point is a number which when put in returns itself (xr + 1 = xr). If we start with numbers near this point (e.g., x0 = 1.5) we get a sequence that converges towards a point (in this case 1). However, if we put in x0 = 2.9, this converges to 1 also. x0 = 3.1 diverges to ∞
Types of Algorithm
The iterative algorithm for computing x will be based on a function of preceding values from this sequence. The function will determine convergence, and care should be taken to ensure convergence exists.
MCS covers two main types of algorithm, one-stage (e.g., Newton-Rapheson) and two-stage (e.g., Aitken's method). Two stage algorithms tend to have faster convergence, but one-stage algorithms have simpler initial conditions.
The type of algorithm we looked at above is a one-stage algorithm called fixed-point iteration. To find the fixed points, a graph is used.
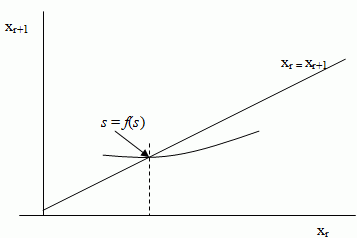
Conditions for Stability and Convergence
- Under what conditions will fixed-point iterations converge or diverge?
- What path does it take?
- How fast does it move along this path? - Can we choose f(x) to optimise convergance?
Fixed Point Iteration
xr+1 = F(xr)
If it converges to s, limr→∞xr = s and s = F(s), then s is called the fixed point of the iteration scheme. If the iterative process is initiallised with x0 = s then it will remain static at the fixed point.
Behaviour Close to the Fixed Point
Suppose xr = s + εr and xr + 1 = s + εr + 1, to converge | εr + 1 | < | εr |, which is equivalent to s + εr + 1 = F(s + εr). If you apply the Taylor series, you can expand this as a polynomial series in ε. F(s + ε) = Σ∞n = 0 anεn
To compute the an coefficient:
- Set ε = 0. F(s) = a0, as the other terms depend on ε and vanish.
- Differentiate - F′(s + ε) = a1 + 2εa2 + 3ε2a3 + ..., then set ε = 0 to eliminate terms containing ε.
- Differentiate again and set ε = 0 gives us F″(s) = 2a2
- Assemble to give us F(s + εr) = F(s) + εrF′(s) + εr2/2 F′(s)
As s = F(s), we can subtract from both sides to give us: εr+1 = εrF′(s) + εr2/2 F′(s). For small values of r, we can ignore εr2 and higher powers. This is the recurance relation for the distance from the fixed point.
So, | εr+1 / εr | ≈ | F′(s) | < 1 is the condition for convergance if for some range of x0 FPI converges to s = F(s), otherwise if there's no such range, it diverges.
Convergance Paths
The sign of F′(s) determines the sign of the the error. sgn(εr + 1) = sgn(F′(s))r+1.sgn(ε0).
The convergance path can be classified as:
- staircase, if F′(s) ∈ (0, 1). This converges to a fixed point from one direction
- cobweb or spiral, if F′(s) ∈ (-1, 0). This jumps from side to side of the fixed point.
Rate of Convergance
The rate of convergance can be considered to be linear if F′(s) ≠ 0. εr + 1 ≈ F′(s)εr2.
We have quadratic convergance if F′(s) = 0 and F″(s) ≠ 0. εr + 1 ≈ (F″(s) / 2)εr2.
Quadratic convergance is much faster than linear convergance. We have the freedom to choose F(x) so that F′(s) = 0
There are limitations to solving non-linear equations using FPI. Non-uniqueness is a problem when choosing the iteration function. For any one G(x) there may be many roots, and many different ways of choosing G(x). There may be no universal F(x) for finding all roots; each root may require its own F(x), and even if there is a universal F(x), the initial values may require careful choice. F(x) may converge at different rates for different roots.
Due to the shortcomings with FPI, we can use the Newton-Raphson method.
Newton-Raphson
In Newton-Raphson, the gradient in the proximity of the root to guide the search. It is a universal scheme, where only one function is needed to find all the roots - provided that there are good initial estimates. Newton-Raphson is also a faster iteration method - it is quadratic.
Probability
See ICM notes for
more about sets
We can consider probabiliy in terms of sets:
- The Universal set - U
- The empty set - ∅
- Union - A ∪ B
- Intersection - A ∩ B
- Disjoint sets - A ∩ B = ∅
- Difference - A - B
- Complement - Ac = U - A
Random Events
Events can be one of two types: deterministic, where the same experimental conditions always give identical answers, or random, where the same experimental conditions give different answers, but the average of a large number of experiments are identical.
In nature, random events occur much more frequently than deterministic.
Sample space
The sample space is the set of all possible outcomes of a random experiment. S is the universal set for the random experiment. Members of S are called sample points. e.g., for a coin toss, S = {H, T}
Sample spaces come in various forms. The first is a discrete sample space which can be either finite (e.g., a dice throw or coin toss) or infinite (defined on the set of positive integers, and are countable). The other sample space is the continuous sample space, which is defined over the set of reals.
Events
Event A is sure if A ⇔ S - this is probability 1. Event A is impossible if A ⇔ ∅ - this is probability 0.
For events A and B, algebra can be used:
- either A or B - A ∪ B
- both A and B - A ∩ B
- the event not A - Ac
- event A and not B - A - B
- mutually exclusive events (can not occur together) - A ∩ B = ∅
Probability is the likelihood of a specific event occuring and is represented as a real number in the range [0, 1]. If P(A) = 1, this is a sure event and P(A) = 0 then the event is impossible.
The odds against is the probability of an event not occuring. P(Ac) = 1 - P(A)
Estimating Probability
Epistemic means
relating to knowledge
There are two approaches to estimating probability, the first is the a priori (epistemic) approach.
If event A can occur in h different ways out of a total of n possible ways, P(A) = h/n. This assumes the different occurances of A are equally likely and is often referred to as the uniform distribution of ignorance.
Aletoric means
relating to experience
The second approach is the a posteriori (aleatoric) approach. If an experiment is repeated n times and the event A is observed to occur h times, P(A) = h/n, however, n must be a very large value for this to be accurate.
We can break down probability in terms of atomic events into a union of events (an event or another event) or an intersection of events (an event and another event). These can be simplified into mutual exclusivity and independance respectively.
Axioms of Probability
If sample space S is finite, the set of events is the power-set of S. If sample space S is continuous, the events are measurable subsets.
For every event: P(A) ≥ 0, however for the sure event, P(A) = 1. However, for mutually exclusive events A1, A2, A3, ... then P(A1 ∪ A2 ∪ A3 ...) = P(A1) + P(A2) + P(A3) ...
The theorems of probability follow the axioms. If A1 ⊂ A2 then P(A1) ≤ P(A2) ^ P(A1 - A2) = P(A1) - P(A2). For every event P(A) ∈ [0,1]. The impossible event has 0 probability P(∅) = 0 and the complementary P(Ac) = 1 - P(A).
Conditional Probability
If you consider two events, A and B, the probability of B given A has occured has the notation P(B|A) which can be expressed as P(B|A) = P(A ∩ B) / P(A), or equivalently P(A ∩ B) = P(B|A).P(A).
Mutually exclusive events are disjoint (i.e., P(A ∩ B) = 0), so P(B|A) = 0.
The probability of a set of independent events which are anded together (e.g., event A and event B, etc) can be expressed as P(A1 ∩ A2 ... An) = ∏ni = 1 P(Ai).
Bayes Theorem
If you consider an event where A1, A2 ... An are mutually exclusive events which could have caused B. The sample space S = Unk = 1, i.e., one of these events has to occur.
Bayes Rule gives us the probability of event B, and is expressed as: 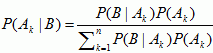 . Bayes theorem is called the theorem of probability of causes.
. Bayes theorem is called the theorem of probability of causes.
Random Variables
If you associate a variable with each point in the sample space, this is referred to as a random or stochastic variable. A random variable is discrete if the sample space is countable, or continuous if the sample space is uncountable.
If you consider a set of discrete random variables, X ∈ {xAk, Ak ∈ S} defined over the sample space S, the probability distribution P(X = xAk) = f(xAk), where f : S → [0, 1], f(x) ≥ 0, ΣAk ∈ Sf(xAk) = 1.
If X is a continuous random variable, the probability that X takes on the value x is 0, as the sample space is uncountably large.
Density Functions
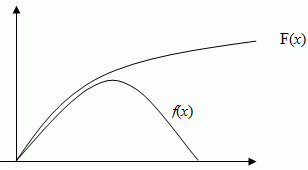
In a continuous distribution, f(x) is defined to mean P(A ≤ x ≤ B) = ∫BAf(x) dx, i.e., the probability that x lies between A and B is equal to the corresponding area beneath the function f(x).
Another method of considering density is cumulative distribution. Here, function F(x) = P(X ≤ x) = P(-∞ < x ≤ x). So, we could say that F(x) = ∫x-∞f(x) dx, hence f(x) = dF(x)/dx.
A graph of F(x) plotted against f(x) may look like:
Bernoulli Trials
A random event (e.g., heads in a coin toss, 4 on a dice) occurs with probability p and fails to occur with probability 1 - p. A random variable X is the number of times the event occurs in n Bernoulli trials.
Discrete Probability Distribution
The random variable X is the event that there are x successes and n - x failures, in n trials. This gives us the probability of successes to be px (where p is the probability of success) and the probability of failures is (1 - p)n - x
There are n!/(x!(n - x)!) ways of getting this Bernoulli Trial, so the probability distribution P(X = x) = (n!/(x!(n - x)!))px(1 - p)n - x, which we call the binomial distribution.
Expectation
The expectation of random variable X is E(X) = Σj xjP(X = xj) if the event is discrete and E(X) = ∫ xP(X = x) dx if the event is continuous. This gives us a value μ of X, which is the expectation of X.
With the expectation, we can derive various theorems:
- If c is a constant and X is any random value, E(cX) = cE(X)
- If X and Y are any random values, E(X + Y) = E(X) + E(Y)
- If X and Y are independent random values, E(XY) = E(X) × E(Y)
Variance
Variance is the expectation of (X - μ)2 → Var(X) = E[(X - μ)2]. Standard devaiation σX = √.
- For any random value X, Var(X) = E(X2) - μ2.
- If c is a constant and X is any random value, Var(cX) = c2Var(X)
- If X and Y are independent random values, Var(X + Y) = Var(X) + Var(Y) and Var(X - Y) = Var(X) - Var(Y).
Binomial Distribution
The binomial distribution has mean μ = np and variance Var(X) = np(1 - p) which gives a standardised random value as Z = (X - np)/√
Poisson Distribution
The binomial distribution is limited for rare events. If there is a large sample (i.e., n → ∞), a small probability (i.e., p → 0), the mean μ = np and variance Var(X) ≈ np, then the distribution can be expressed as P(X = x) = (μxe-μ)/x!
Normal/Gaussian Distribution
The limiting case of the binomial distribution is when n → ∞. P(Z = z) = 1/√ e-z2/2, which is the normal distribution.
A non-standardised random value x is Gaussian if P(X = x) = 1/(σx√ e-(x - μ2)/(2σ2). The sample space here is the set of reals (i.e., x ∈ R), which means x is a continuous random value.
This approximates the binomial with a standardised random value (Z = (X - np)/(np(1 - p)) when n is large and p is neither close to 0 or close to 1.
Formal Languages and Automata
We have the problem of an Ada compiler not knowing whether or not an Ada program is legal Ada, and not English, FORTRAN or some other illegal language. To start with, we can look at the problem of recognising individual elements (variable names, integers, real numbers, etc) and then building these together to make a full language recogniser (a lexical analyser). One definition may be that variable names always start with a letter which is then followed by a sequence of digits and letters. We can draw a transition graph to describe what a legal variable is composed of.
Transition Graphs
Transition graphs are pictoral representations of a regular language definition
![]()
A transition graph consists of states, an initial state, a final state (also called acceptor states) and named transitions between the states. The double ringed value represents the final state. In the above transition graph, 1 is the initial state and as 2 can not get to the final state, this is an illegal state.
From the transition graph, a transition table can be drawn up, for the above example:
| letter | digit | EOS | |
| 1 | 3 | 2 | error |
| 2 | error | error | error |
| 3 | 3 | 3 | accept |
Proving Automata by Induction
Assume we have an on-off switch, we can define S1(n) as automata is off after n pushes if and only if n is even and S2(n) as the automata is on after n pushes if and only if n is odd. We can prove ∀n, S1(n) ^ S2(n) using induction.
As usual, we need to prove the base case (S1(0) ^ S2(0)) by considering implication in both directions, and prove for n + 1.
Central Concepts
An alphabet is a finite non-empty set of symbols, e.g., Σ = {0, 1} or Σ = {a, b, c ... z}, etc
A string is a sequence of symbols of the alphabet, including the empty string (λ). Σk is the set of strings of length k (however, Σ ≠ Σ1). Σ* is the unions of all strings of length k ≥ 0. Σ0 = λ. We can also define the set that includes the empty string as Σ+ = Σ* - λ
In strings, (assume a ∈ L) an means a...a (a n times). If w = abc and v = bcd, then wv = abcbcd. Prefixes are anything that forms the start of a string and a suffix is anything that forms the end of a string. The length of a string is the number of symbols in it and this can be represented using |w|.
A language is a set of strings chosen from some Σ*. L is a language over Σ: L ⊆ Σ*. Languages are sets, so any operation that can be performed on a set can be performed on a language, e.g., is the complement of L.
Models of Computation
Automata are abstract models of computing machines. They can read input, have a control mechanism (a finite internal state), a possibly infinite storage capability and an output. In this course, we will mainly be considering finite state automata (FSA) - machines without storage or memory. An important point to consider is that some problems are insoluble using finite state automata, and more powerful concepts are needed.
Deterministic Finite State Automata (DFA)
The DFA is specified using a 5-tuple, M = ⟨Q, Σ, δ, i, F⟩, where
- Q is a finite set of states
- Σ is a finite set of possible input symbols (the alphabet)
- δ is a transition function, such that Q × Σ ← Q
- i is the initial state (i ∈ Q)
- F is a set of final states (F ⊃ Q)
DFA's accept string S, if and only if (i, S) ∈ F, where the transition function δ is extended to deal with strings, such that (q, aw) = (δ(q, a), w). λ is accepted by M, if and only if i ∈ F.
A language L is accepted by an FSA M if and only if M accepts every string S in L and nothing else.
Non-deterministic Finite State Automate (NDFA)
The definition of a DFA is such that for every element of the input alphabet, there is exactly one next state (i.e., δ is a function). An NDFA relaxes this restriction, so there can be more than one next state from a given input alphabet, so the transition function becomes a relation ρ.
There are advantages of non-determinism. Although digital computers are deterministic, it is often convenient to express problems using NDFAs, especially when using search. For example, the following NDFA definining awa, where w ∈ {a, b}* is a natural way of expression:
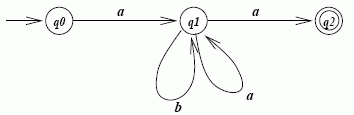
Any NDFA can be converted into a DFA by considering all possible transition paths in a NDFA and then drawing a DFA where a node is a set of the nodes in an NDFA.
We can formally define an NDFA as a tuple M = ⟨Q, Σ, ρ, i, F⟩, where:
- Q is a finite set of states,
- Σ is a finite set of possible input symbols (the alphabet)
- ρ is a transition relation, ⊃ 2Q × (Σ ∪ {λ}) × Q
- i is an initial state (i ∈ Q)
- F is a set of final states (F ⊃ Q)
ρ can also be defined as a transition function which maps a state and a symbol (or λ) to a set of states.
Hence, we can say a string S is accepted by NDFA M = ⟨Q, Σ, ρ, i, F⟩ if and only if there exists a state q such that (i, S, q) ∈ and q ∈ F, where the transition relation is extended to strings by (q, aw, r) ∈ , if and only if there exists a state p such that (q, a, p) ∈ ρ ^ (p, w, r) ∈ . The empty string λ is accepted by M if and only if i ∈ F.
λ Transitions
λ transitions are a feature of an NDFA. A transition does not consume an input symbol and these transitions are labelled with λ.
When converting an NDFA to a DFA with a λ transition, you always follow a λ transition when plotting the possible paths.
Converting an NDFA to a DFA
We could say that a DFA was a special case of an NDFA, where there are no non-deterministic elements. From the formal definitions of a DFA and NDFA, we could hence prove that for any NDFA, an equivalent DFA could be constructed.
If M is an NDFA ⟨S, Σ, ρ, i, F⟩, then we can construct DFA M′ = ⟨S′, Σ, δ, i′, F′⟩, where:
- S′ = 2S
- i′ = {i}
- F′ is those subsets of S that contain at least one state in F
- δ is a function from S′ × Σ into S′ such that for each x ∈ Σ, s′ ∈ S′, δ(s′, x) is the set of all s ∈ S such that (u, x, s) ∈ ρ for some u ∈ s′. In other words, δ(s′, x) is the set of all states in S that can be reached from a state in s′ over an arc named x.
Inductive proof exists
in the lecture slides
Since δ is a function, then M′ is a DFA. All that needs to be done is prove that M and M′ accept the same strings. We can do this using induction on the string length, and using path equivalence to show that any string accepted by an NDFA is accepted by the same equivalent DFA.
Regular Languages
A language L is regular if a DFA or NDFA exists that accepts L. If M is a DFA, L(M) is the language accepted by M. Every finite language is regular.
See notes for proof
of set operations
If we consider a regular language as a set, we can perform set operations on one or more regular languages, and still get regular languages out.
However, not all languages are regular and can not be represented by a DFA. For example, if we consider Scheme expressions, these have a balanced amount of opening and closing brackets, but these can not be represented by a DFA.
The proof for the pumping
lemma is on the lecture slides
We have a theorem called the pumping lemma that states, if a language contains strings of the form xnyn for an arbitarily large n ∈ N then it must also contain strings of the form xnym where n ∋ m.
Regular Expressions
Instead of using machines to describe languages, we switch to an algebraic description - this is a more concise way of representing regular languages.
In regular expressions, + represents union, juxtaposition represents concatenation (note, some books use . for concatenation) and * is the star closure. For example:
| language | regular expression |
| {a} | a |
| {a, b} | a + b |
| {a, b} ∪ {b, c} | (a + b) + (b + c) |
| {a, b}* ∪ {aa, bc} | (a + b)* + (aa + bc) |
| {a, b}*{ab, ba}* | (a + b)*(ab + ba)* |
| {a, b}* ∪ {λ, aa}* | (a + b)* + (λ + aa)* |
Formal Definition
Let Σ be an alphabet. ∅, λ and a ∈ Σ are regular expressions called primitive regular expressions. if r1 and r2 are regular expressions, then so are r1 + r2, r1r2, r1* and (r1). A string is a regular expression if and only if it can be derived from primitive regular expressions by finite number of applications of the previous statement. Every regular language defines a set of strings; a language.
The lecture slides contain the proof of this.
Generalised Transition Diagrams
A full set of examples
exist in the lecture notes
We can extend transition diagrams to have transitions which consist of regular expressions, making them more flexible and powerful.
Finite Automata with Output
Moore Machines
A Moore machine is a DFA where the states emit output signals. Moore machines always emit one extra symbol (i.e., the output has one symbol more in the output string than the input string) and have no accepting state. In a Moore machine, the state name and the output symbol are written inside the circle.
Mealy Machines
A Mealy machine is the same as a Moore machine, but it is the transitions that emit the output symbols. This means that Mealy machines generate output strings of the same length as the input string. With Mealy machines, the output symbols are written alongside the transition with an input symbol.
Are Mealy and Moore machines equivalent?
Let Me be a Mealy machine and Mo be a Moore machine.
Previously, our definition of equivalence meant that both machines accept the same string, however here, we need to define a new concept of equivalence, so we say that the machines are equivalent if they both give the same output. Under this definition, equivalence will always be a contradiction as Mealy and Moore machines will always generate strings of different lengths, given the same input. We must also disregard the first character output from a Moore machine.
Constructing the Equivalence
To change Moore machines into Mealy, each state needs to be transformed where the output on the state is put on each transition leading to that state. This can be proved by induction, but it is easier to prove by inspection.
Converting a Mealy machine to a Moore machine is harder, as multiple transitions with different outputs can arrive at the same state. To work round this, you need to replicate a state, such that all transitions into a particular state give the same output and then the above transformation process can be reversed. Again, this is proved by inspection.
Pumping Lemma for Regular Languages
Let L be any infinite regular language. There then exists strings x, y, z (where y ≠ λ) such that: ∀n > 0, xynz ∈ L
- Let M be a DFA with n states that accepts L
- Consider a string w with length greater than n that is recognised by M
- Thus, the path taken by w visits at least one state twice
- With this information, we can break the string into three parts:
- let x be the prefix of w, up to the first repeated state (x may be λ)
- let y be the substring of w which follows x, such that if it travels round the circuit exactly once it returns to the same state (this must not be λ)
- let z be the remainder of w
- Thus, w = xyz
- Hence, M accepts any string in the form xynz (where n > 0) and could be represented as:
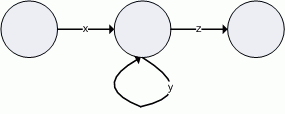
To apply the pumping lemma, you should assume some language L is regular and generate a contradiction. However, this is not perfect, for example, in the case of palindromes. so additional methods must be applied based on the length of symbols in the FSA to create a contradiction.
Decidability
A problem is effectively soluble if there is an algorithm that gives you the answer in a finite number of steps - no matter on the inputs. The maximum number of steps must be predictable before commencing execution of the procedure.
An effective solution to a problem that has a yes or no answer is called a decision procedure. A problem that has a decision procedure is called decidable.
Equivalence of Regular Expressions
How do we conclude whether or not rwo regular expressions are equal? "Generating words and praying for inspiration is not an efficient process".
A regular expression can be converted into a finite automaton by means of an effective procedure, and vice versa. The length of the procedure is related to the number of symbols in the regular expression or the number of states in the finite automaton. We can test the languages are equivalent by:
- producing an effective procedure for testing that an automaton does not accept any strings
- looking at the automaton that is constructed by looking at the differences between the two machines
- if this difference automaton accepts no strings, then the languages are equivalent
The Complement of a Regular Language
If L is a regular language over alphabet Σ then = Σ* - L is also a regular language. To prove this, we need to consider:
- The DFA M = (Q, Σ, δ, i, F) such that L = L(M) and the DFA is a completion (no missing transitions - that is (q0, w) is always defined).
- = L(N), where N is the DFA N = (Q, Σ, δ, i, Q-F), that is, N is exactly like M, but the accepting states have become non-accepting states, and vice versa.
Closure Under Intersection
Proving that the intersection of two regular languages is regular is easy as we can use boolean operations, specifically de Morgan's law. That is, L1 ∩ L2 = ¬( ∪ )
This can be constructed explicitely also. If L1 and L2 are regular languages, so is L1 ∩ L2. This can be proved by:
- considering two languages, L1 and L2 and automata M1 and M2. Here, assume L1 = L(M1) and L2 = L(M2) and that M1 = {Q1, Σ, δ1, i1, F1}, M2 = {Q2, Σ, δ2, i2, F2}
- notice the alphabets of M1 and M2 are the same, this can be done because in general, Σ = Σ1 ∪ Σ2
- construct M such that it simulates both M1 and M2. States of M are the pairs of states first from M1 and the second from M2. When considering the transitions, suppose M is in the state (p, q) where p ∈ Q1 and q ∈ Q2. If a is an input symbol, we have δ(p, q), a) = δ1(p, a), δ2(q, a), presuming that we have completed DFAs.
Closure Under Difference
If L and M are regular languages, so is L - M. This is proved by noting that L - M = L ∩ . If M is regular than is regular and because L is regular, L ∩ is regular
Testing for Emptiness
If we have two languages, L1 and L2 defined either by regular expressions or FSAs, we can produce an FSA which accepts (L1 - L2) + (L2 - L1) - this is the language that accepts strings that are in L1 but not L2, or are in L2 but not L1. If L1 and L2 are the same language, then the automaton can not accept any strings.
To make this procedure an effective procedure, we need to show we can test emptiness. We can create an effective procedure using induction. The base case is that from the start case, at least the start case is reachable. The inductive step is that if state q is reachable from the start state, there is an arc from q to p with any label (an input symbol or λ), then p is reachable. In this manner, we can compute the set of reachable states. If the accepting state is among them, then the FSA is not empty, otherwise it is.
You can also test by regular expression to see if the FSA is empty. Here, the base step is that ∅ denotes the empty language and any other primitive expression does not. The inductive step is that if r is a regular expression, there are four cases:
- r = r1 + r2, then L(r) is empty if and only if L(r1) and L(r2) are empty.
- r = r1r2 is empty if and only if either L(r1) or L(r2) are empty.
- r = r1* then L(r) is not empty, as this always includes λ
- r = (r1) then L(r) is empty if and only if L(r1) is empty.
Testing for Equivalence
Now we can give a procedure for checking whether two regular languages are equivalent:
- Construct M1 = M(L1) and M2 = M(L2)
- Construct and
- Construct M1 ∩ and M2 ∩
- Construct (M1 ∩ ) ∪ (M2 ∩ )
- Prove the constructed automaton is empty
Testing for (In)finiteness
If F is an FSA with n states, and it accepts an input string w such that n < length(w), then F accepts an infinite language. This is proved with the pumping lemma.
If F accepts infinitely many strings then F accepts some strings such that n < length(w) < 2n. This is proved by saying:
- If F accepts an infinite language, then F contains at least one loop.
- Choose path with just one loop
- The length of this loop can not be greater than n
- Then one can construct a path with length at least n + 1 but less than 2n by going round the circuit the required number of times.
We can then generate an effective procedure. If we have an FSA with n states, we can generate all strings in the language with length at least n and less than 2n and check if any is accepted by the FSA. If it is, the FSA accepts an infinite language; if not, it does not.
Minimising a DFA
For an example,
see lecture 7
Is there a way to minimise a DFA? States p and q are equivalent if and only if for all input strings w, (p, w) is accepting if and only if (q, w) is accepting. That is, starting from p and q with a given input, either both end up in an accepting state (not necessarily the same one) or neither does (not necessarily the same). States p and q are distinguisable if there is at least one string w such that one of (p, w) and (q, w) is accepting and the other is not.
One efficient way of accomplishing this is using the table filling system. For DFA M = (Q, Σ, δ, i, F), if p is an accepting state and q is non-accepting, then the pair {p, q} is distinguishable. The inductive step is that is p and q are states such that for some input symbol a, r = δ(p, a) and s = δ(q, a) are a pair of states known to be distinguishable then {p, q} is a pair of distinguishable states.
The procedure can be performed by filling up a table starting with the states we can distinguish immediately. At the end of the process, those states not marked will show the equivalent states.
The states eventually become an equivalence relation: reflexive, symmetric and transitive. The automaton can be minimised by substituting states for equivalent states
Context-Free Grammars
Context-Free Grammars (CFGs) are very easy to write parsers for, and many computer langauges are context free, such as DTDs for XML.
CFGs consist of a series of productions, rules which define what the language can do, as well as non-terminal symbols, defined by productions and terminal symbols, which exist in the language we are trying to define.
The context-free grammar for the language anbn is S → ab | λ, where our non-terminal symbol is S, the terminals are a and b and "S → ab | λ" is our production.
To make a more formal definition of a context-free grammar, we could start with a grammar and then restrict it to be context-free.
A grammar is specifiec to be a quadruple G = <V, T, S, P> where
- V is a finite set of nonterminal (or variable) symbols
- T is a finite set of terminal symbols (disjoint from V)
- S ∈ V and is the start symbol
- P is a finite set of production (or rules) in the form of α → β, where α and β ∈ (V ∪ T)* and α contains at least one non-terminal
By convention, we use capital letters for non-terminals and small letters for terminal symbols.
To tighten up the above definition to be a context-free grammar, α should consist of a single non-terminal.
Parsing
There are two ways to show a particular string is in the language of a grammer. The first involves working from the string towards S, e.g.,
- S → NP VP
- VP → VT NP
- NP → peter
- NP → mary
- VP → runs
- VT → likes
- VT → hates
So, to parse the string "peter hates mary" using the above CFG, the parsing process would look like:
- peter hates mary
- NP hates mary
- NP VT mary
- NP VT NP
- NP VP
- S
It is also possible to work from S towards the string, and this process is called deriving. For example, we could have:
- start with S
- S → NP VP, so rewrite S to NP VP, the notation for this is S ⇒ NP VP
- NP VP ⇒ peter VP
- peter VP ⇒ peter VT NP
- peter VT NP ⇒ peter hates NP
- peter hates NP ⇒ peter hates mary
Formally, we can express derivations as, given a string of symbols αβγ, where α, γ are strings from (V ∪ T)* and β is a string from (V ∪ T)+ and a rule β → δ, we can derive αδγ replacing β with δ:
- we write αβγ ⇒ αδγ to indicate that αδγ is directly derived from αβγ
- we are generally interested in the question "Is there a sequence of derivations such that α ⇒ ... ⇒ δ
In our example, we could have written peter VP ⇒ ... ⇒ peter hates mary. We say that peter VP derives peter hates mary, and this is written as peter VP ⇒* peter hates mary.
However, this leaves room for mistakes, as it relies on intuition.
To reduce some (but not all) non-determinism from a derivation, we can consider two types of derivations, left most and right most. In the left most derivation, the left most nonterminal is replaced, and in a right most derivation, the right most nonterminal is replaced. A left most derivation is indicated by: ⇒lm* and a right most one by ⇒rm*.
S ⇒* w ⇔ S ⇒lm* w ^ S ⇒* w ⇔ S ⇒rm*
Parse/Derivation Trees
These are graphical representations of derivations. For example, for the left most derivation given above, the parse tree would look like:
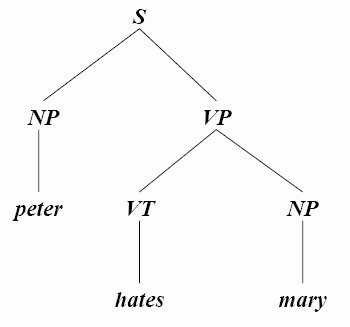
Ambiguity
We can consider different sentences to be semantically ambiguous, so different interpretations would give us different parse trees. For example, for the phrase "Tony drinks Scotch on ice", Tony could either be drinking the drink "Scotch on Ice", he could be drinking Scotch whilst stood on some ice.
In natural language, ambiguity is part of the language, however in computer languages, ambiguity is to be avoided.
Parsers
- Parsing is the process of generating a parse tree for a given string.
- A parser is a program which does the parsing.
- Given a string as input, a parser returns a (set of) parse tree(s) that derive the input string.
Languages Generated by a Grammar
- A grammar G generates a string α if S ⇒* α, where S is the start symbol of G.
- A grammar G generates a language L(G) if L(G) is the set of all terminal symbols that can be generated from G, i.e., L(G) = {α ∈ T* | S ⇒* α}
Context Free Grammars and Regular Languages
Not all context free grammars are regular, however some are. All regular languages can be expressed by a CFG. A CFG can be express all languages, however.
For a given CFG, the semiword is a string of terminals (maybe none) concatenated with exactly one variable on the right, e.g.,: tttV.
To prove this, we have to theorise that for any given finite automaton there is a CFG that generates exactly the language accepted by the FSA, i.e., all regular languages are context free. This is proved using a construction algorithm - we start with an FSA and generate a CFG:
- The variables of the CFG will be all the names of the states in the FSA, although the start state is renamed S.
- For every edge labelled a ∈ Σ ∨ λ, the transition a between two nodes (A and B) gives a production A → aB (where B = A in the case of a loop)
- An accept state A gives us A → λ
- The initial state gives us the start symbol S
Now we can prove that this CFG generates exactly the language accepted by the original FSA by showing that every word accepted by the FSA can be generated by the CFG and every word generated by the CFG is accepted by the FSA (we know in general that this is not possible, but our CFG has a particular form).
If we consider some word, say abbaa, accepted by the FSA, then we can construct the path through the FSA to an accepting state through a sequence of semi-paths. These semi-paths are formed from the string read from the input followed by the name of the state to which the string takes us.
- start in S, we have a semipath of S
- read a and go to X, semipath: aX
- then read b and go to Y, semipath: abY
- ...
- read the final a and go to semipath abbaaF
- as F is an accepting state, the word abbaa is accepted
This corresponds to a derivation of the string using the productions already generated from the FSA.
To prove the second statement we have to express every word of the CFG in the form of N → tN, thus every working string found in a derivation from this CFG must contain only one nonterminal and that will be at the very end, thus all derivations from this CFG give a sequence of semiwords, starting with S and corresponding to a growing semipath through the FSA. The word itself is only generated by the final accepting nonterminal being turned into a λ - this means the semipath ends in an accepting state, and the word generated is accepted by the FSA.
We have a final theorem to complete our proof: If all the productions of a CFG are either of the form N → semiword or N → word (where the word may be λ).
- Draw a state for each nonterminal and an additional state for the accept state
- For every production of the form Nx → wyNz, draw a directed arc from Nx to Nz
- If Nx = Nz then loop
- If Np → wq then we have a final state
- Thus, we have constructed a transition graph
- Any path in the transition graph from start to accept corresponds to a word in the language of the transition graph and also to the sequence of productions from the CFG which generate the same word. Conversely, every derivation of a word corresponds to a graph.
- Therefore, this form of CFG is regular.
Regular Grammars
A grammar G = <V, T, S, P> is a regular grammar if all rules in P are of the form:
- A → xB
- A → x
where A and B are non-terminals and x ∈ T* (i.e., x is either λ or a sequence of terminal symbols).
Thus, we see that all regular languages can be generated by regular grammars, and all regular grammars generate regular languages. But, it's still quite possible for a CFG which is not in the format of a regular grammar to generate a regular language.
Ambiguity in CFGs
Ambiguity is particularly a problem if we want to compare parsed structures, e.g., structured files. A CFG is ambiguous is there exists at least one string in the language accepted by the CFG for which there is more than one parse tree.
The question we need to ask is whether or not we can develop an algorithm that removes ambiguity from CFGs. There is no general algorithm that can tell us whether or not a CFG is ambiguous (this is discussed further in TOC).
If L is a CFG for which there exists an unambiguous grammar, then L is said to be unambiguous. However, if every grammar that generates L is ambiguous then the language is inherently ambiguous.
Are there techniques that might help us avoid ambiguity? We can look at the two causes of ambiguity:
- no respect for precedence of operators, a structure needs to be forced as required by the operator precedence
- a group of identical operators can group either from the left or from the right. It does not matter which, but we must pick one
A technique for removing ambiguity is introducing several new variables each representing those expressions that can share a level of binding strength.
Total Language Trees
The total language tree is the set of all possible derivations of a CFG starting from the start symbol S. We can use total language trees to get an idea of what kind of strings are in the language. Sometimes (but not always), the are useful to check for ambiguous grammars.
However, if an identical node appears twice in a total language tree, this does not necessarily mean the language is ambiguous, as the parse trees could just be the difference between left most and right most derivations.
Pushdown Stack Automata
Pushdown Stack Automata are like NDFA, but they also have a potentially infinite stack (last in, first out) that can be read, pushed and popped. The automaton observes the stack symbol at the top of the stack. It uses this and the input symbol to make a transition to another state and replaces the top of the stack by a string of stack symbols.
The automaton has accept states, but we will also consider the possibility of acceptance by empty stack.
A non-deterministic pushdown stack automaton (NDPA) is defined by P = (Q, Σ, Γ, δ, q0, z0, F).
- Q, Σ, q0 and F are defined as before - states, input symbols, initial states and accept states
- Γ is a finite set of symbols called the stack alphabet
- z0 ∈ Γ is the stack start symbol. The NDPA stack consists of one instance of this symbol in out outset
- δ is revised for NDPAs. As this is a non-deterministic automaton, the result is a set of states, so we can define δ as a function to a set of pairs of stacks and states. δ takes a state q ∈ Q, an input symbol a ∈ Σ or λ the empty symbol and a stack symbol z ∈ Γ, which is removed from the top of the stack and produces a set of pairs: a new state and a new string of stack symbols that are pushed onto the stack. If the stack is to be popped then the new string will be empty (λ). Hence, δ : Q × (Σ ∪ {λ}) × Γ → 2(Q × Γ*). (note, this is restricted to finite subsets)
Instantaneous Descriptions
To compute an NDPA, we need to describe sequences of configurations. In the case of an FSA, the state was enough. In the case of an NPDA, we need stacks and states.
The configuration of an NPDA is called the instantaneous description (ID) and is represented by a triple (q, w, γ), where q is the state, w is the remaining input and γ is the stack. As before, we assume the top of the stack is the left hand end.
In DFAs and NDFAs, the notation was sufficient to describe sequences of transitions through which a configuration could move, however for NPDAs, a different notation is required.
├P, or just ├ (when P is assumed) is used to connect two IDs. We also use the symbol ├* to signify there are zero or more transitions of the NDPA. The basis of this is that I ├* I for any ID I, and inductively, I ├* J, if there exists some ID K such that I ├ K and K ├* J, that is, I ├* J if there exists a sequence of IDs K1,...,Kn, and ∀i = 1, 2, ..., n - 1, Ki ├ Ki+1
We can also state the following principles of IDs:
- If a sequence of IDs (a computation) is legal, then adding an additional input string to the end of the input of each ID is also legal
- If a computation is legal, then the computation formed by adding the same string of stack symbols below the stacks for each ID is also legal
- If a computation is legal and some tail of inputs is not consumed then removing this tail in each case will not affect the legality
We can express these more formally:
- If P = (Q, Σ, Γ, δ, q0, z0, F) is an NPDA and (q, x, α) ├*P (p, y, β), then for any strings w ∈ Σ* and γ ∈ Γ* it is also true that (q, xw, αγ) ├*P (p, yw, βγ). This captures the first two principles above, and can be proved by induction.
- If P = (Q, Σ, Γ, δ, q0, z0, F) is an NPDA and (q, xw, α) ├*P (p, yw, β), then it is also true that (q, x, α) ├*P (p, y, β). This captures the third principle above
Acceptance by Final State
The language accepted by final state by a NDPA P = (Q, Σ, Γ, δ, q0, z0, F) is: L(P) = {w ∈ Σ* | (q0, w, z0) ├*P (q, λ, α), q ∈ F, α ∈ Γ*}. Note that in this definition, the final stack content is irrelevant to this definition of acceptance.
Acceptance by Empty Stack
For an NPDA P, the language accepted by empty stack is defined by N(P) = {w|(q0, w, z0) ├* (q, λ, λ)}, for any state q ∈ Q. (note that the N here indicates null stack).
For full proof, see Hopcroft
Motwani and Ullman
"Introduction to Automata
Theory, Languages and
Computation", page 231.
The class of languages that are L(P) for some NDPA P is the same for the class of languages that are N(P), perhaps for a different P. This class is exactly the context free languages. The proof of this is based on constructing the relevant automata.
When discussing acceptance by empty stack, the final states (final component) of the NPDA are irrelevant, so are sometimes omitted.
Converting from empty stack to final state
If L = N(PN) for some NPDA where PN = (Q, Σ, Γ, δN, q0, z0), then there is a NPDA PF such that L = L(PF). Diagrammatically, this looks like:
![]()
We let x0 be a new stack symbol, the initial stack symbol for PF and we construct a new start state, p0 whose sole function is to push z0, the start symbol of PN onto the top of the stack and enter state q0, the start state of PN. PF simulates PN until the stack of PN is empty. PF detects this because it detects x0 on the top of the stack. The state pf is a new state in PF which is the accepting state. The new automaton transfers to pf whenever it discovers that PN would have emptied its stack.
We can make a formal definition of this accepting state machine as: PF = (Q ∪ {p0, pf}, Σ, Γ ∪ {x0}, δF, p0, x0, {pf}), where δF is defined by:
- δF(p0, λ, x0) = {(q0, z0x0)}. PF makes a spontaneous transition to the start state of PN pushing its start symbol z0 onto the stack.
- ∀q ∈ Q, a ∈ Σ ∪ {λ}, y ∈ Γ, δF(q, a, y) contains at least all the pairs in δN(q, a, y)
- In addition, (pf, λ) ∈ δf(q, λ, x0), ∀q ∈ Q
- No other pairs are found in δF(q, a, y)
It can be shown that w ∈ L(PF) ⇔ w ∈ N(PN). This fact is later used as a proof about languages that an NPDA will accept.
Converting from final state to empty stack
The construction to do a conversion from an acceptance by final state automata to an acceptance by empty stack machine is PN = (Q ∪ {p0, p}, Σ, Γ ∪ {x0}, δN, p0, x0).
![]()
δN is defined by:
- δN(p0, λ, x0) = {q0, z0x0}. The start symbol of PF is pushed onto the stack at the outset and then goes to the start value of PF.
- ∀q ∈ Q, a ∈ Σ ∪ {λ}, y ∈ Γ, δN(q, a, y) ⊇ δF(q, a, y). PN simulates PF.
- (p, λ) ∈ δN(q, λ, y), ∀q ∈ F, y ∈ Γ ∪ {x0} - whenever PF accepts, PN can start emptying its stack without consuming any more input.
- ∀y ∈ Γ ∪ {x0}, δN(p, λ, y) = {(p, λ)}. Once in p when PF has accepted, PN pops every symbol on its stack until the stack is empty. No further input is consumed.
Equivalence of NPDAs and CFGs
We have shown from our final state to empty stack theorem that if we let L to be L(PF) for some NPDA PF = (Q, Σ, Γ, δF, q0, z0, F) then there is a NPDA PN such that L = N(PN). We can then show that the following classes of language are equivalent:
- context free languages
- languages accepted by final state in an NPDA
- languages accepted by empty state in an NPDA
If we have a CFG G, the mechanism is to construct an NPDA that simulates the leftmost derivations of G. At each stage of the derivation, we have a sentential form that describes the state of the derivation: xAα, where x is a string of terminals. A is the first nonterminal and α is a string of terminals and nonterminals. We can call Aα the tail of the sentential form, that is, the string that still needs processing. If we have a sentential form of terminals only, then the tail is λ.
The proposed NDPA has one state and simulates the sequence of left sentential forms that the grammar uses to derive w. The tail of xAα appears on the stack with A on the top.
To figure out how the NDPA works, we suppose that the NDPA is in an ID (q, y, Aα) representing the left sentential form xAα. The string being parsed w has form xy, so we are trying to match y against Aα. The NPDA will guess non-deterministically one of the rules, say A → β as appropriate for the next step in the derivation. This guess causes A to be replaced by β on the stack, so, (q, y, Aα) ├* (q, y, βα). However, this does not necessarily lead to the next sentential form as β may be prefixed by terminals. At this stage, the terminals need to be removed. Each terminal on the top of the stack is checked against the next input to ensure that we have guessed right. If we have not guessed right, then the NPDA branch dies. If we succeed then we shall eventually reach the left sentential form w, i.e., the terminal string where all the symbols of the stack have been expanded (if nonterminals) or matched against input (if terminals). At this point, the stack is empty and we accept by empty stack.
For proof, see
lecture notes
We can make this more precise by supposing F = (V, T, S, R) is a CFG and the construction of NPDA P is as follows: P = ({q}, T, V ∪ T, δ, q, S) (this NPDA is accepting by empty stack), where δ is defined as:
- A ∈ V, δ(q, λ, A) = {(q, β) | A → β ∈ R}
- a ∈ T, δ(q, a, a) = {(q, λ)}
To convert from an NPDA to a CFG, a similar approach is used, but in the other direction. Our problem is that given an NPDA P, we need to find a CFG G whose language is the same language that P accepts by empty stack. We can observe that:
- a fundamental event as far as an NPDA is concerned is the popping of a symbol from the stack, while consuming some input - this is a net process and may involve a sequence of steps including the pushing of other symbols and removal
- this process of popping the element may involve a sequence of state transitions, however there is a starting state at which the process begins and an ending state where it finishes.
In the construction of the grammar below, we use the following notation: nonterminals are associated with the net popping of a symbol, say X and the start and finish states, say p and q for the popping of X. Such a symbol is in the form [pXq].
If we let P = (Q, Σ, Γ, δ, q0, z0, F) be an NDPA, then there is a CFG G such that L(G) = N(P). We can construct G = (V, Σ, S, R) as follows:
- Let a special symbol S be the start symbol
- Other symbols: [pXq] where p and q are states in P and Q and X ∈ Γ
- Productions (R) for all states p we have S → [q0z0p]. This generates all the strings that cause P to pop z0 while going from q0 to p, thus for any string w, (q0, w0, z0) ├* (p, λ, λ)
- Suppose δ(q, a, X) contains the pair (r, Y1...Yn) where a = Σ ∪ λ then for all lists of states r1...rn G includes the production [qXrn] → a[rY1Y1]...[rn-1Ynrn]. This production says that one way to pop X and go from q to state rn is to read a (which may be λ) and then use some input to pop Y1 off the stack while going from r to r1, then read some input that pops Y2, etc...
In order to prove that P will accept strings that satisfy this grammar we have to prove that[qXp] ⇒* w ⇔ (q, w, X) ├* (p, λ, λ)
Deterministic Push Down Automata (DPDAs)
A DPDA provides no choice of move in any situation. Such choice might come from:
- More than one pair in δ(q, a, x)
- A choice between consuming a real input symbol and making a λ transition.
P = (Q, Σ, Γ, δ, q0, z, F) is deterministic exactly when:
- δ(q, a, x) has at most one member for any q ∈ Q, a ∈ Σ ∪ {λ}, x ∈ Σ
- If δ(q, a, x) is non empty for some a ∈ Σ, then δ(q, λ, x) must be empty
DPDAs accept all languages by final state that are regular, but there are also some non-regular languages that are accepted. DPDAs do not accept some context-free languages. All languages accepted by DPDAs are unambiguous, however not all inherently unambiguous languages are accepted by a DPDA.
Simplifying CFGs
Every context free language can be generated by a CFG in which all productions areof the form: A → BC, or A → a. This form is called the Chomsky Normal Form. To get to this form, we need to perform various steps.
Firstly we remove useless symbols. For a symbol to be useful, it must be both generating and reachable. X is generating if X ⇒* w, for some terminal string w. Every terminal is therefore generating. X is reachable if there is a derivation S ⇒ αXβ for some α and β.
To compute generating symbols, we have the basis that every terminal in T is generating. The inductive step is that if there is a production A → α and every symbol of α is known to be generating then A is generating.
To compute reachable symbols, we have the basis of S being reachable and the inductive step of supposing variable A is reachable. Then, for all productions with A as the head (LHS), all the symbols of the bodies of those productions are also reachable.
For the next step, we need to eliminate nullable symbols. A is nullable if A ⇒* λ. If A is nullable, then whenever A appears in a production body, A may or may not derive λ.
To compute nullable symbols, we have the base step that if A → λ is a production of G, then A is nullable. Inductively, if there is a production B → C1C2...Ck, where each Ci is nullable, then B is nullable. Ci must be a variable to be nullable. The procedure for this is:
- Suppose G = (V, T, S, P) is a CFG
- Determine all the nullable symbols
- Construct G1 = (V, T, S, P1), where P1 is determined as follows: Consider A → X1X2...Xk ∈ P, k ≥ 1. Suppose m of the k Xis are nullable then the new grammar will have 2m versions of this production, where nullable Xis are present and absent. (If m = k, then don't include the A → λ case, otherwise if A → λ is in P, then remove this production)
The final step is to remove unit productions: A → B, where A and B are variables. These productions serve no use, so can be removed. However, we need to take care when identifying cycles. The procedure for identifying unit pairs, A ⇒* B using only unit productions, has the base step of (A, A) is a unit pair, as A ⇒* A. Then by induction, if (A, B) is a unit pair and B → C is a production where C is a variable, then (A, C) is a unit pair.
To eliminate unit productions, if we're given a CFG G = (V, T, S, P), then construct G1 = (V, T, S, P1) by finding all the unit pairs, and then for pair (A, B), add to P1 all the productions A → α where B → α is a non-unit production of P.
Now we have the three processes for converting a CFG to an equivalent minimised CFG, we have to consider a safe order for performing these operations to ensure a minimised CFG. This is:
- Remove λ productions
- Eliminate unit productions
- Eliminate useless symbols
Chomsky Normal Form
To reduce a grammar to the Chomsky Normal Form, we have to perform the following procedure:
- Remove λ productions, unit productions and useless symbols, as above. As a result, every production has the form A → a, or has a body of length 2 or more.
- For every terminal that appears in a production body of length 2 or more, create a new variable A and a production A → a. Replace all occurances of a with A in production bodies of length 2 or more. Now each body is either a single terminal or a string of at least 2 variables with no terminals.
- For bodies of length greater than 2, introduce new variables until we have all bodies down to length 2.
The Chomsky Normal Form is helpful in decidability results. For instance, it can turn parse trees into binary trees and is therefore able to calculate the longest path and is then bound on execution time.
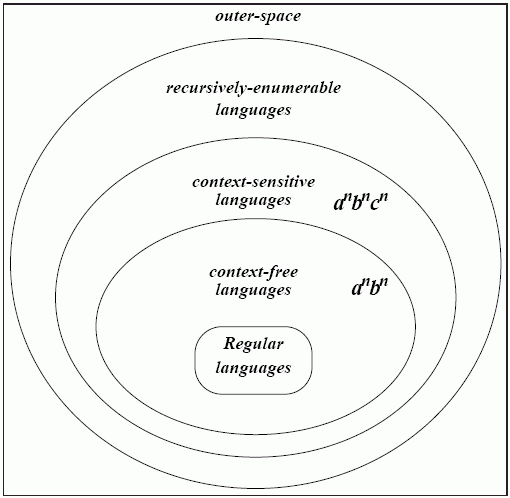
Chomsky Hierarchy of Grammars
Chomsky proposed the following classification for grammars in terms of the language they generate.
| Grammar Name | Restriction on α → β | Langage Generated | Accepting Automata |
|---|---|---|---|
| Unrestricted (type 0) | α contains at least one non-terminal | Recursively enumerable | Turing machine (a general purpose computing machine with infinte memory and read/write operations on memory). Transitions can take into account the contents of any memory location |
| Context-sensitive (type 1) | α contains at least one non-terminal and |α| ≤ |β| | Context-sensitive | Linear-bounded automata (like a Turing machine, but with finite memory and restrictions on usage) |
| Context-free (type 2) | α is a single non-terminal | Context-free | Non-deterministic pushdown automata |
| Regular (type 3) | α is a single non-terminal and β is a sequence of terminals (possibly zero) followed by at most one non-terminal | Regular | Finite state automata |
This can be represented by Venn diagram.