Systems
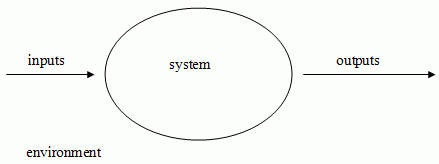
A system is contained within a boundary, either physical or logical. Outside the boundary is the environment, which the system interacts with via inputs and outputs. The system has no direct control over the environment, it can only control what happens inside the boundary. The system receives inputs, but has no control over what these inputs are. It gives outputs but has no control over what then happens to them.
Systems can be defined in many ways. They could have the same boundary, but a different way of looking at it. It could also have a different boundary. For example, you could look at a computer system in the following ways:
- A tool that takes commands and returns data
- A collection of components that take in electrical signals and returns electrical signals
- A device for converting characters to binary code
- A component in an office workflow diagram
A system is analogous to mathematical relations. A system maps inputs to outputs. This is an abstraction level which is sufficient for many purposes.
Systems are nested, therefore decomposition is normally a good way to study a system. Systems can "overlap" (at least logically). Definitions can be applied to all systems.
To design a system:
- Determine boundary
- What can be changed
- What is in the scope of design, what is outside
- Determine the interfaces/how it interacts with the environment
- Determine mapping relations
- Determine what internal data is required to support mappings
- Data storage
To design a system to work into an existing system, you need to think of separate components. Each component contains a boundary and an interface, and I/O mappings. How the system works should be transparent to each other module. All you need to know is:
- How to use the interfaces (I/O structures)
- What the mappings achieve
- How trustworthy the components are
Hierarchies
Systems are hierarchical structures. Each level is a component of a higher level, and each component also has components at lower levels. Some components and levels are logical. Each topic in Computer Science tries to deal with one level at a time. Mixing levels of hierarchy can lead to confusion.
Science and Engineering
Science explores the physics of computing, i.e., what happens in energy terms, what the components are and why they behave as they do and the theory underpinning hardware and software.
Engineering studies ways to build systems. It looks at the hardware and software, and the network and systems architectures.
Generalisation of Engineering
Engineering principles in one area usually apply in some form in other areas (one principle can be applied to, say, civil engineering, just as much as CS). For example, good practice in development, documentation and testing principles, the planning and management, dealing with cost effectiveness and professional oversight are all traits of engineers.
Students rarely meet reality, however engineering is based in reality. Reality is big, messy and imprecise. Reality changes goals and resources during projects, demands evidence of performance and wants things to last forever (but then discards them the following week).
As reality is often too much for engineers to conceive, they simplify it using models. Models are representations of reality. Programs, diagrams, mathematical definitions, CAD, working scale models are all examples of models. Models are used to abstract away detail that is not relevant to the current purpose. Models can be static (diagrams, maths, etc) or dynamic (programs, train layouts, animated CAD drawings, etc).
Lifecycles
All engineering projects can be characterised in general terms:
- Requirements
- Specifications
- Designs
- Implementations
- Testing
- Maintenance
- Decommission
We will briefly look at each. You should apply these principles in other modules. There are lots of lifecycle models (waterfall, spiral, etc) that can be used. Lifecycles are abstract summaries of a chaotic reality - don't expect models to be perfect, but they shouldn't be dismissed either.
Development methods are different to lifecycles. The methods are practical help with the development based on expertise/experience of experts.
Requirements
This is what the system is required to do. This is a constraint also - you should not be making the system do things that is beyond the requirements. Requirements are quite general, as this is looking at the system from a high level. At lower levels, requirements are more specific to a particular architecture, platform, etc...
Testing happens against the requirements, therefore the requirements need to be objective and clear. Requirements also change, and these changes must be documented. Engineers aim to just meet the requirements; extras are not needed, or in some cases desired.
Specification
A specification is a contact for a development. It meets the requirements and is an abstract description of the requirements - it is not how the requirements are going to be achieved. It could use diagrams, mathematics or logical analysis. It needs to be rigorous and unambiguous. It should be checked against the requirements.
VVC (Verification, Validation and Certification)
Verification - This checks that the data is factually correct.
Validation - This checks that the data fits in with it's intended use.
Certification - The checks a system against external documentation and operational standards.
Design
This is less abstract than a specification, however still does not contain any code. There may be different design at different levels. A design also adds more constraints.
Implementation
This must match the design. It also includes documentation - both of the development and for the users. Implementation is a trivial stage compared to the specification and designs, if they are done right.
Some tips for implementation are:
- Re-use code where ever possible
- Document the original or re-used code
- Document all change and the rationale behind those changes to re-used code.
- Write re-usable code
- Use a good style of coding and document your coding fully
- Document how procedures and packages are used
- Document what each component does and the conditions they take.
Testing
This is the most important part. It is dependent on the earlier parts and consists of various parts:
- Unit tests - this tests the internal code
- Module, integration and system tests - testing the individual components and composition verification
- Acceptance or certification testing - validation that works as intended in context and within standards
Testing reveals errors, not correctness; it is impossible to show a program is perfect. Tests should be designed to break the system; you should always be testing for unexpected things (e.g., illegal inputs, out-of-range data). Testing should occur close to or on the boundary of the operational envelope.
The specification and design should be used to identify meaningful tests.
Maintain
Most systems change after delivery, perhaps a new platform is introduced, etc... Bug fixes may also need to be applied. Documentation and code needs to be maintained..
Regression testing should be performed.
- Work out what tests should and should not still work
- Run all your tests again and check the results
- Don't just test the changed parts.
Decommission
Few systems are ever thrown away. If a system is used, it is likely to be replaced. You should try to reuse and recycle. There could be lessons to be learnt from an old system, requirements and scenarios could be similar to the new system, components might need to be retained and each of these elements requires careful analysis.
Documentation is crucial
Computer Hierarchy
A computer is a hierarchy of parts (a system). There are many overlapping hierarchies and views, logical and physical views are both hierarchical and you can look at things from both a functional and architectural point of view. ICS only covers some of the views and hierarchies that exist.
Events
Any input is an event. A command or data sent may change the system state. How an event is determined depends on your view, for example from the view of the CPU only electrical pulses are valid. Logically this could be a single character, a signal, etc... From a human view, this could be a string of text, or a whole mouse movement (which relates to multiple signals).
Keyboard Events
Stallings 7.1
A keypress sends electrical signals to a keyboard transducer. The transducer converts the character pressed to an IRA (ASCII) bit value.
Mouse Event
Press, release, etc are all considered individual mouse events. The window manager interprets events and movements to commands. Commands are interpreted to machine instructions in the form of bits.
Bits are transmitted to the I/O module and memory. Transmission of input is identical for all bits. In a window, a window manager interprets key presses and mouse movements to machine instructions or data.
A filename is a logical reference to a distributed set of addresses. Physically this is an index address and lots of separate data blocks.
A computer takes well formed commands and then uses context to deduce what's intended.
Views and Levels
Stallings 1.1
There are different ways you can look at things:
- Internals - above the hardware level but below the operating system
- Architecture - how the programmer sees the system
- Organisation - how features are laid out
Architecture
- Data representation
- Instruction set
- Addressing
- I/O mechanisms
Most of these are logical abstractions. Physical signals represent bits and they represent instructions and addresses.
Organisation
- Internal signals, clocks and controllers
- Memory addressing
- Instructions
- Hardware support
Structures and Functions
Stallings 1.2
| Structure | Functions |
| CPU | storage |
| Memory | processing |
| I/O | movement |
| communications | control |
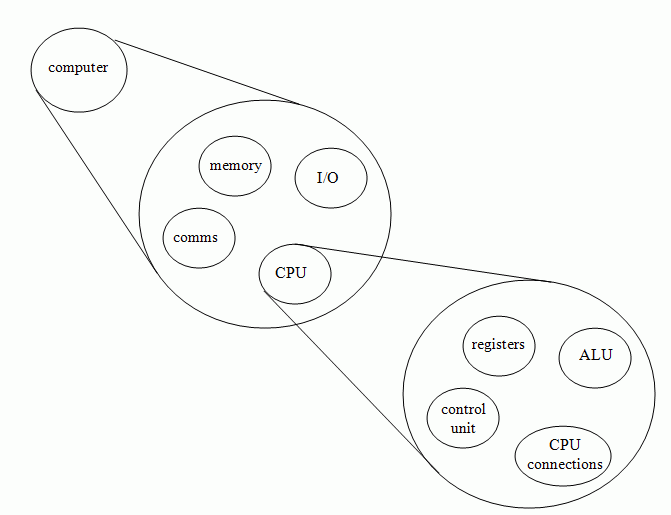
- control unit - controls execution cycle
- ALU - computational core
- registers - internal memory
- connections - connections between other units
IAS
Stallings 2.1
John von Neumann was at the Princeton Institute for Advanced Studies (IAS). He came up with the theory for a stored-program computer in about 1945. The first IAS machine was completed in 1952. Although this is later than Turing's efforts in the 1940's, the IAS system was public and open from inception so became more well known.
The IAS architecture stored data and instructions in a single read/write memory. The memory contents were addressable by locations and sequential execution from one instruction to the next occurred.
Main Memory
Main memory is a collection of locations, each holding a binary value. Instructions are stored and read sequentially in one set of addresses. A logical abstraction of this is a stack. All locations have sequential identities (addresses) which data is stored and accessed by.
Architecture functions and organisation are built round groups of addresses.
| instruction | 0 |
| instruction | 1 |
| instruction | 2 |
| instruction | . |
| instruction | . |
| instruction | x |
| data | x+1 |
| data | x+2 |
| data | . |
| data | . |
| data | n-1 |
| data | n |
Main memory has n locations. Instructions are in locations 0-x. The instruction stack is a logical data structure with input at the top, and reads happen at the top too.
Words and Bits
Each memory location is 1 word. The IAS machine had 1000 words in memory. The Intel 8088 (1979) had 1 MB. The current Pentium 4 (IA32) architecture has 64 GB of words.
Each word contains a fixed number of bits. The IAS had 40-bits words, but most modern systems have 2n bits, for example, Intel processors until the 386 had 16 bit words. Early Pentium's had 32 bit words and the Pentium II onwards had 64 bit words.
There are many formats for a word. The simplest is the opcode followed by an operand. The opcode identifies one machine instruction (operation). The operand is the address of data to be operated on.
Fetch-Execute Cycle
Computer operations are in a series of cycles. For example, retrieve a word from main memory, execute instruction in a word, etc..
Instructions locations number logically from 0. When the computer systems, a program counter (pc) is set (i.e., to 0). This causes the 0th instruction to be fetched. Instruction is then executed and the pc is incremented. The first instruction is executed next. The fetched instruction is written to the instruction register (ir) for execution.
The pc and ir are CPU registers, like main memory, but fast and inside the CPU. pc and ir are CPU registers. The pc only needs to hold an address. CPU buffers are common, for example, between the pc, ir and main memory. Buffers could include the mar (memory address register) and the mbr (memory buffer register)
The CPU control unit determines when to fetch an instruction. The communication between the main memory and the CPU uses buses for addresses, control signals and data. The control uses a clock tick (this is a regular pulse signal). The control units ticks to start the next element of the F-E cycle.
Fetched instructions might need more memory interaction because an execution can take place - this is an indirect cycle.
The execution that occurs depends on the instruction in the ir. For example, it could be
- moving data among registers, from CPU to main memory, etc
- modifying control
- I/O
- ALU invocation
Interruptions
Assume end-to-end execution of stored programs. The CPU is very efficient compared to other peripherals and the F-E cycle is faster than other devices. Rather than the CPU hanging and waiting for a device, interruptions allow the CPU to continue with another instruction and return to one that's waiting on a device when the interrupt is called.
Different types of interrupts exist:
- Program Interrupts - Illegal processing attempted (for example, a divide by 0, arithmetic overflow or an illegal memory call)
- Timer Interrupts - Allow regular functions to occur (housekeeping, polling for data, etc)
- Device Interrupts - Come from device controllers, such as I/O. These signals could be such as "ready", "error", etc.
- Hardware Failure Interrupts - Power out, memory parity error, etc.
Device Handling
A processor fetches an instructiowww.n which involves a device call. The execution calls a set-up program (I/O program) which prepares buffers for data, etc... The device driver (an I/O command) is then called and the execution terminates.
Preparing for an Interrupt Cycle
This is a variant of the fetch cycle. The current pc is stored in a dedicated address. After the interrupt is completed, the control unit reads the stored pc value and resumes at that location.
The CPU knows addresses to be used. The interrupt only starts when the previous instruction is fully executed.
Interrupt Handling
Any device may send an interrupt (signalling that it is ready for I/O, etc), however the handling details are specific - it might include the OS for example.
Computer Connections
Devices inside a computer are connected using buses, lines and interfaces.
There are many different types of connections - point-to-point (a dedicated link) or a bus (a link shared by many components). A bus corresponds to a particular traffic type - data, addresses, etc...
Networking can be wired or wireless. Conceptually it is different to internal communications, but physically it is becoming similar to buses. Bus and network protocols are slowly converging.
Internal and external communications have different emphases. Networking has an emphasis on security, whereas buses tend to emphasise robustness.
Buses link at least two components, and traffic is available to all logical components connected to that bus. Logically, a bus is dedicated to either data, addresses or control signals. Physically, a bus comprises of a bundle of separate bus lines.
Buses are things passing values - like a flow of communications. In reality, it carries current, so has values at all points simultaneously - logically this is either 1 or 0. Unfortunately transfer isn't really instant (assuming that it is is a level of abstraction). A pulse that is either on or off doesn't exist in the real world. There is a leading edge and a trailing edge as voltage rises or falls. These edges don't carry any data and signals are not relevant here.
Buses use serial communications, i.e., 1 bit at a time. There are 8 lines for an 8 bit bus.
Parallel buses are buses of serial lines. Each bus still carries one thing, but a communication may be split over many buses. In theory, parallel is faster and more efficient, however serial buses tend to have higher data rates due to the overhead of parallel (assembly and disassembly of packets).
Early buses had separated, unsynchronised clocks - CPU time was wasted waiting for devices to catch up. Modern buses are controlled by a single CPU clock, however, variable speeds are being re-introduced according to application.
Data Bus and Lines
Data buses have one bus line per bit in a word (or multiples of this), e.g., 32-bit words have 32 (or a multiple of this) data lines, each requiring its own connection pin.
Address Bus and Lines
Buses may have a memory-I/O split. Most significant bit may say whether it's intended for memory or an I/O address.
Control Bus and Lines
These are normally sufficient with 1 bit. They carry things such as timing signals (clock/reset), command signals and interrupt signals.
Modules and Interfaces
Stallings 3.3, 3.4, 7.5
Each computer component is a module with an interface. It is based on the engineering principle of each module being self-contained with minimal interfaces. This is true of modules in any other engineering (software, etc)
Memory Interface
The memory interface passes fixed length words to the memory. The memory doesn't care what it's storing, it could be an address or data, or anything.
Control signals (read signal, write signal) tell the memory module what to do, the address bus carries the address that's being considered, and the data bus will either carry the contents of the memory to or from the memory.
CPU module
The CPU is "intelligent". It identifies the content of the data bus to be different types and deals with them accordingly.
Coming in, it has control signals (interrupts) and data signals (instructions and data). Going out it gives out control signals, addresses and data.
DMA
To save CPU cycles, an architectural extension called Direct Memory Access allows the I/O module to read/write directly to memory. DMA modules control access between I/O and memory. It must avoid clashing with the CPU however - a common approach to solve this is cycle stealing. Cycle stealing happens like this:
- The CPU is in the normal FE cycle
- It sends a write signal to the DMA
- Outputs to the data bus - the address of I/O and memory and the number of words to be written
- CPU resumes FE cycles
The DMA only has 1 data register. It only reads one word at a time and writes a word to the I/O device. The DMA also has a data count register. It holds the number of words it is supposed to transfer and it is decremented after each transfer. When the data count register is 0, it sends an interrupt to the CPU to signal it is ready.
This only works for memory to I/O. I/O to memory using DMA isn't implemented in most systems, but is essentially the same thing in reverse.
The DMA tends to interact with the FE cycle like this. The CPU and DMA module share control of devices. CPU cycles are suspended before bus access occurs and an interrupt is sent to the DMA. The DMA finishes transferring the current word and releases bus control, sending a signal to the CPU control unit. When the CPU finishes using the bus, it signals the DMA to resume.
Stallings 7.13
CPU suspend is not the same as an interrupt - context is not saved and the CPU does nothing else whilst it is interrupted. The CPU simply waits one bus cycle then takes control.
DMA pause is also not an interrupt. The DMA has no other role in computation, so cannot defer tasks to a later date.
Module Bus Arrangements
Stallings 3.4
A very simple arrangement is as follows:
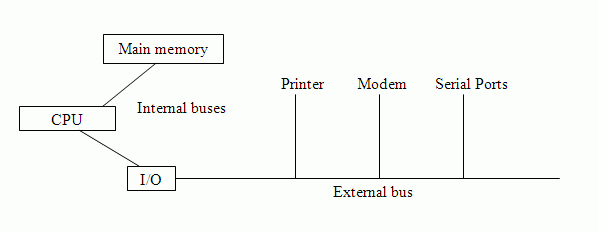
However, with external buses there are propagation delays. It takes time to co-ordinate bus use. More components or devices requite long buses, and this makes co-ordination slower. Buses also tend to be bottlenecks, the classic example of this being the "von Neumann bottleneck". Ways to alleviate delays may involve deeper hierarchies (using caches and bridges), dedicated buses for high-volume traffic and separation of slow and fast devices. A more accurate bus diagram may look like this, for example:
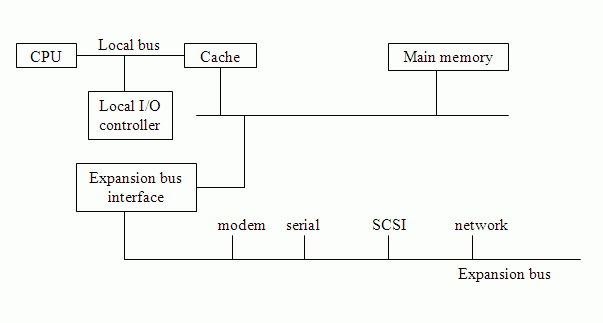
However this is still a gross simplification. In reality, there are many more layers than this.
Memory Hierarchy
Memory can be simply split up into two forms, internal (registers, caches, main memory, etc) and external (hard disc drives, memory sticks, etc)... The focus in ICS is on internal.
Total storage space is typically expressed in bytes. The size of a byte was variable in earlier architectures, but now is standardised on 8 bits. An alternative way of expressing memory is using words. A word is a "natural" unit of memory, and is architecture specific. Typically, a word is the length required to represent a number or instruction (commonly 8, 16, 32 bits, etc). There are many exceptions to this though - variable/multiple word lengths, word lengths not in the form of 2n, etc...
Addressable units are the memory locations recognised. Each unit is a word length and the address range is built into the architecture. There are many exceptions, however, the most common being byte-level addressing within words. The number of addressable units is 2n where n is the number of address bits. 16 bit addressing can cope with 216 units, or 65536. These are number from 0 to 65535, for example.
A unit of transfer is physically the number of data lines connected to memory. There are exceptions to this, for example partial words being read, etc...
External transfer units are called a block.
Memory Access and Performance
Different architectures have different methods. Older forms used external memory, which use sequential/direct access. Newer architectures tend to use random or associative access.
Stallings 6
Access time is dependent on architecture, hardware and organisation. ICS considers these for random access memory. The parameters used to measure performance are access time )or latency), memory cycle time and transfer rate.
Latency
This is the inevitable delay whilst processing a command. For reads, the access time is the time from the request of an address to the memory until the data is ready to use. For writes, the access time is the time from presentation of the address and data until the write process is completed.
Cycle Time
Cycle time is the gap between memory access - for example waiting for memory to stabilise, buses to reset, etc...
Transfer Rate
This is the rate at which data can be transferred in and out of memory. It's the reciprocal of the cycle time.
Physical Media
This needs to be stable and hold two clearly distinct values, such as semiconductor, magnetic media, optical discs, etc...
Memory Volatility
Volatile memory requires a power source to maintain state. Memory such as cache is volatile.
Memory Hierarchy
| Inboard Memory | Register |
| Cache | |
| Main memory | |
| Outboard Storage | Magnetic disc |
| Optical | |
| Off-line Storage | Magnetic Tape |
| Magnetoptical | |
| Write Once Read Many |
As you move down the hierarchy, you get a lower cost per bit, greater capacity, slower access and rarer use by the CPU.
More information on memory is available on the course web pages.
Errors and Error Correction
Stallings 5.2
Errors can occur in the semi-conductor. Hard errors are permanent errors where a cell is always stuck at 0 or 1, or a random value. Soft errors are unintended events changing cell values, physical causes, power surges, alpha particles, etc.
Error detection works on the principle of storing two values, m - the data - and k, which is a function of m.
If m has M bits and k has K bits, then the stored word is M + K bits. When m is read, f(m) is calculated again, giving k', which is compared to the stored value of k.
If k' and k are the same, no error has been detected, however if they're different, two things can occur. m gets sent to the corrector and corrected, if it's correctable, and if not, an error is reported.
This gives three various levels of detection: no detection, uncorrectable detected error, or correctable detected error. However, this is not always accurate. An error could have gone undetected, or a corrected error may not still give the right value.
An early method of detection was parity, which was 1 bit long. If the stored number is even, parity is 0, otherwise if it's odd it's 1. If a double bit flip occurs, no error is detected, so it is limited. Also, it can not correct detected errors.
Hamming Error Detection
This improves detectiblity (known as Hamming distance) and also maximises the data:parity bit ratio (the information rate).
The Hamming distance is the minimum number of bit flips that cannot be detected. For parity, this is 2.
Because there is also the chance that parity is incorrect, embedding parity in the data increases the chance of it being accurate. Only one error in parity gives a parity error.
If two bits are flipped, but corrections applied then an even more wrong number will be extracted. Combining old style parity with Hamming allows you to check between single bit flips and two-bit flips. If parity is right, but Hamming is wrong, you know 2 bit flips have occurred, so no correction is possible. This type of method is known as SEC-DED (single error correction, double error detection) and it is considered adequate for most modern systems. The probability of error is quite low.
Cache Memory and Memory Addressing
Stallings 4
Caching works on block of memory contents, rather than single words. For example, a 16-bit main memory address may identify a block of data (where a block is 4 words in this example). In this case, this make 000016 the start of the first block, 000416 the start of the second, etc... A word is then identified by its offset from the start.
Caching is used to improve memory performance (it was first introduced in 1968 on the IBM S/360-85) and has become a feature of all modern computing. Cache is typically the fastest memory available and behaves like a module in the CPU.
All information is still held in main memory. The cache holds copies of some memory blocks (recently accessed data). CPU reads are initiated as normal, the cache is checked for that word, and if it's not cached, the block is fetched into cache and the CPU gets served directly from cache.
Main memory consists of 2n words with unique addresses 0 to 2n - 1 assigned to blocks of K words. This makes 2n / K blocks. Cache consists of C lines of K words, where C holds a block. C <<< M.
There are many different ways of implementing cache. The most common is that all buses lead to cache and the CPU has no direct memory access (logically).
The cache needs to know which memory block contains which word. Two ways of accomplishing this is with direct mapping and associative mapping.
Direct Mapping
A section of memory is mapped to one line in cache. This is simple and cheap. However, swapping could happen a lot. Two blocks which are accessed a lot by a program are mapped to the same cache line. The program causes these lines to be constantly swapped in and out, this is called "thrashing" and wastes CPU time.
Associative Mapping
Here, any memory block can map to any cache line. The main memory needs a block tag and word, the cache just needs a block tag. This isn't as fast to look up, as more lines need to be checked for a particular word.
There are further cache issues to consider, for example, what happens when a cache line is overwritten. A delete/write policy needs to be defined, the block and line size needs to be considered, and there could be multiple caches.
CPU
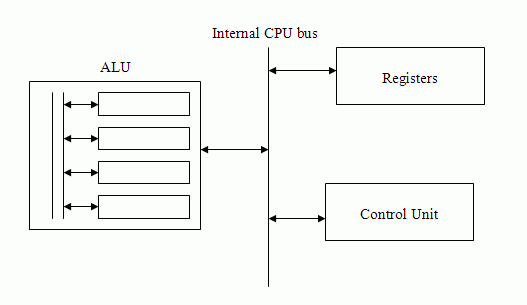
The ALU performs computation and the other CPU units exist to service the ALU. The ALU is made of simple digital hardware components. It stores bits and performs Boolean logic operations. All data comes to and from registers, input is from the control unit and outputs goes to registers, with status flags going to the control unit. As a module, the ALU may be made up of more modules (4 common ones are the status flag, the shifter, the complementer and the boolean logic unit).
Status Flag
This is linked to the status register, or program status word. All CPUs have at least one.
Condition codes and other status information may consist of:
- The sign of the result of the last operation
- A 'zero' flag (if the last operation returned 0)
- Carry (for multi-word arithmetic operations)
- Equal (a logical operation result)
- Overflow
- Interrupt
Shift and Complement
This is a very common ALU component and is a computational function that occurs frequently. It can be solved using addition, but it normally more efficient to use shifts.
Shifting multiplies or divides by 2. 11111111 may become 11111110 if multiplied or 01111111 if divided.
There are also circuits for boolean logic and arithmetic, but the implementation details vary from architecture to architecture.
Registers
CPUs normally have two types of registers, general-purpose (or user-visible), which are accessible from low level languages and allows for optimisation of memory references by the programmer and control & status registers - the control unit controls access to these. Some are readable, and some are also allowed to be written to by the OS, for example, to control program execution.
Instructions
A computer operates in response to instructions. The lowest representable form is machine code (binary). This is normally represented in hex, however, as it is easier to read. The first human-readable form of the code is assembly, which is a textual representation of machine code.
Instructions have an opcode and an operand(s). The opcode names a particular CPU operation. The operand is either data, or related to the data (an address, for example), or a number, etc... In some cases, operands may be implicit.
Many simple operations combine to form fetch-executions, etc. Sometimes these are called micro-instructions.
Normally, there is 1 opcode and up to 4 operands. The format of the instruction is architecture dependent. Architecture designs have different representations for data types and how the CPU distinguishes them.
Representations
Representing Integers
Binary natural numbers aren't a problem for computers, however, integers are signed (can be positive or negative) and normally the msb represents the sign (-ve is binary 1 and +ve is binary 0). Therefore, a binary representation of an integer must contain the sign and the magnitude. The advantage to this method is that negation can happen due to a single bit flip, however, there are now two different representations of 0 and arithmetic must consider both sign and magnitude.
Another method of representing integers is the two's complement method. Here, a positive number has msb 0. In 4 bits, 1111 is the largest representable negative and 0111 is the largest representable positive. The range of representable numbers is -2n-1 to 2n - 1 - 1. For 4 bits, this gives us +7 to -8. 0 is always positive. The main advantages to this method of representation is that there is a single representation of 0, and the arithmetic is simpler (for a computer).
Representing Real Numbers
Real numbers are identified by a 32-bit word. There is a 1 bit sign, 8 bit exponent and 23 bits for the significand. This is defined by the IEEE 754 floating point standard. IEEE 754 also defines the 1,11,52-bit standard for 64 bit systems and extended standards which can be used in the internals of a CPU only. The standard also gives standard meanings for extreme values, e.g., 0 is represented by all 0s, infinity is represented by all 1s in exponent and 0s in the significand, etc... A de-normalised number should have an all-0 exponent, whereas all 1s in the exponent and a non-0 significand represents 'NaN' - not a number.
Underflow (the numbers get too close to 0 - i.e., too precise for the 32-bit word to represent) and overflow (numbers get too large) occurs when the exponent can't represent all bits. 0 can not be represented as a floating point.
For integers, a normalised floating point 32-bit word can hold one of 232 values. Some values are too precise to represent so they get rounded to the nearest one - in the case of underflow errors this is 0.
There is a trade off between precision and range by changing the number of exponent and significand bits.
Stallings 9.5
Exceptions are errors - where something different happens from normal expectations. Exceptions tend to be raised by a program and can occur at any level - exception handling is an essential part of good programming at all levels.
Representing Characters
Text is a thing that you don't do arithmetic on. It consists of printable characters (such as this text) and non-printing characters (newline, escape, bell, etc). Characters are coded in an order and this can be exploited for inequality and mathematical ordering ( 1 < A < a < } )
Computers store binary values, so text must be encoded. The most standard encoding (until recently) was ASCII, but others existed such as the International Reference Alphabet (IRA, IA5), EBCDIC, etc... These traditionally used 7-bits, but extended forms were available. Normally, a parity bit was added to pad it to 8 bits for storage.
International standards have taken longer to develop, and have only recently come to dominate. Most of these standards are derived from ASCII. The modern international standard is Unicode, which was developed by ISO. Unicode was originally 16-bit, but nowadays can be up to 32.
Representing Other Objects
There are far too many to discuss in detail, but other items, such as images, sound, video, etc... needs to be represented also. These are traditionally done using large data structures with special handling procedures.
Addressing Modes
Addresses have several modes, identified by operand types, special flag bits, etc...
Address (A) is the contents of the instructions' address field.
Register (R) is used in specialised addressing modes where contents of the address field refers to a register.
Effective Address (EA) is address of an actual operand location.
(X) means the contents of memory location X.
Immediate
A = Operand. There is no separate memory reference and this can be used to set constants or initialise variables.
e.g., LOAD 11111001 . Loads a two's complement value in an 8-bit address field. When stored, it is padded to word or address size.
This mode is not very common due to capacity limitations
Direct Addressing
The operand holds the effective address. EA = A.
This means there is one memory reference per operand, however there is still limited address space and for this reason it is not used much.
Indirect Addressing
Operand points to a memory location, which points to EA. EA = (A).
The operand is smaller than a memory word - but the possible addresses are still limited. The memory location is a full word, and any address is possible. This method of addressing is used in virtual memories.
Register Addressing
The address directly refers to a CPU register.
Register Indirect Addressing
The address is in a register, not main memory, otherwise it's the same as indirect.
Displacement Addressing
This combines direct and register indirect.
EA = A + (R)
There are three common variants to this:
- relative addressing - program counter is the displacement
- base-register addressing - the register is implicit
- indexing - the reverse of base-register. This is fast for iteration.
Stack Memories
Stacks are standard computer data structures. A sequence of memory locations are applied to for a stack memory. Stacks operate as FILO, so access is only to the top item in memory. You "push" to an empty address above the current top and "pull" to get the current top address.
Stallings 10 appendix A
An area of memory is reserved for stack. A pointer is directed to the current top address in a dedicated stack pointer register, because of this, stacks use register indirect-addressing. The top few items in a stack may be in a register or cache for fast access.
With stacks, instructions don't need addresses. The opcode always operates on the top value.
Assembler and Machine Code
Stallings 10
To execute an instruction, each element is read and decoded in turn. Micro-operations occur for decoding addresses and data and then the instruction cycle is a sub-unit of the execution.
The CPU and instructions should be designed to remove any ambiguity.
The instruction cycle works like this:
- CPU: Calculate next instruction address
- Memory: Fetch next instruction
- CPU: Decode instructions (using micro-instructions, where are arch dependant) and get input operands, opcodes and output operands.
- CPU: Calculate address of input operands
- Memory: Fetch the address and return the data
- CPU: Perform the operation (determined by the opcode) on the data.
- CPU: Calculate the output address
- Memory: Store the output
- CPU: Loop to the next item in the F-E cycle.
The exact instruction cycle varies according to the architecture (there may be multiple operands, implicit operands, etc)...
The maximum amount of operands any instruction needs is 4 - two input, 1 result and the next instruction reference. However, due to implicitness, a 4 operand instruction set is rare. 1 or 2 operands instruction sets are common.
Reverse Polish Notation
Reverse Polish Notation is useful when coding for a 1 operand instruction set. The format always gives correct precedence and it is most easily envisaged as a graph.
There are different ways of representing machine code:
- Machine code - binary codes that map directly to electrical signals.
- Symbolic instructions: Assembler - mnemonic codes and addresses (normally hexadecimal). This needs to be "assembled" in machine code.
- High-level programming language - needs to be compiled and assembled.
The instruction set determines functionality and capabilities, and also how easy programming is. More instructions require more opcodes, and therefore more space, but it makes coding easier.
There are many issues in dispute about instruction set design, the hardware has never been stable enough for consensus to occur.
Types of Operation
Stallings 10.3
In 1998, J Hayes said there were 7 types of operation which instructions can be grouped into.
- Data Transfer - apply to transfer chunks of data (e.g., MOVE, LOAD, STORE, SET, CLEAR, RESET, PUSH, POP). These are usually the simplest operations to build.
- Arithmetic - ADD, SUB, MULT, etc...
- Logic - like arithmetic, but for any value, for example NOT (bit flipping/twiddling), AND, EQUAL, bit shifting, etc...
- Conversion - translation between numeric formats (floating point/integer, normalised/denormalised), length translations, etc...
- I/O - can either be memory mapped (the I/O addresses are in memory address space, so only one set of instructions is needed for both I/O and memory) or isolated (separate addresses and opcodes for I/O and memory)
- System Control - usually only available to CPU and OS, allows access to privileged states and instructions, e.g., modifying special registers (program counter, etc).
- Transfer of Control - breaking the normal F-E cycle, essentially overriding the program counter. Using these instructions you can implement thinks like loops (JMP), conditionals (Branch if). You can call procedures with a CALL command, which runs a new program in the F-E cycle. RETURN then goes back to where you CALLed from to continue. A stack of CALL locations allows you to implement multiple levels of procedures.