Introduction to Speech Technology
Speech processing aims to model and manipulate the speech signal to be able to transmit (or code) speech efficiently, to be able to produce natural speech synthesis and to be able to recognise the spoken word. Since speech is the natural form of communication between humans, it reflects a lot of the variability and complexity of humans. This makes modelling speech an interesting and difficult task.
The speech signal contains information from many levels and encodes about the speaker and the acoustic channel - the words and their pronunciation, the language syntax and semantics, etc. The lowest level is that of the digitised speech signal from the human user, which can be captured using a waveform coder. Above this level you can do signal analysis to get some speech parameters which can be used with a parametric coder and synthesiser. Further analysis (pattern classification) results in speech symbols which can be used with a segment vocoder for coding and for parameter control for the speech synthesiser. The highest level involves linguistic decoding, resulting in text which can be coded as natural language dialogue, and then word-to-phoneme conversion used for the highest level of the synthesiser.
At these low level, there are no phonetic content, but speech technologies include signal-to-noise ratio estimation, pronunciation quality measurement, pitch extraction and noise suppression. The middle levels have no semantic content but the technologies here include phone recognition, pronunciation training, keyword spotting, emotion detection, speaker and language identification. The higher levels contain semantic, but no discourse or pragmatic content and the key technology here is speech recognition. Even higher analysis can be done (summarisation, dialogue systems, etc) using natural language processing. Only at the low level are the quantities we are dealing with continuous; at the higher levels they're discrete.
Speech Classification
Classification is the task of assigning a sample to a particular class in a finite set (e.g., a phoneme, word or speaker), hence most speech technology tasks use classification techniques. The most complex speech technology task is automated speech recognition (ASR), but most other tasks derive their algorithms from ASR principles.
Pattern classification is one of the most important tasks in pattern processing. The task is to identify patterns in the input data such that the data can be assigned to one out of a finite number of classes Ci. All pattern processing techniqes make use of the fundamental pattern classification paradigm: Given an example x, feature extraction is used to obtain a representative vector y, which can be classified into a class c.
Speech Recognition
A distinction is usually made between recognition (the identification of the words in an utterance - an orthographic transcription) and understanding (an indication of the meaning of the utterance). You can go a long way building an ASR without understanding, and this course only covers recognition.
Historically, there have been differences in the philosophy to approach these different aspects of ASR. For recognition, pattern matching techniques were used, and syntax/semantics learnt from statistics and not separated - the knowledge is implicitly learnt from lots of data. Stochastic systems are used with powerful algorithms to automatically optimise formal mathematical models for a given task. For understanding, systems were historically based on the extraction of perceptually important features and the use of linguistic rules. Much use was made of explicitly coded syntax, semantics and pragmatics, which were rule-based and deterministic with many interacting, ad-hoc rules.
This traditional approach for speech understanding is no longer used since is gave poor performance as the capabilities of speech recognisers grew. Modern speech understanding systems use text produced by a speech recognition system (sometimes with multiple hypotheses) and then do further text interpretation. The current dominance of statistical models using parameters estimated from large corpora has also influenced computational linguistics, where this approach is getting more interest.
Speech is a complex combination of information from different levels (discourse, semantic, syntactic, phonological, acoustic) that is used to convey a message. This signal contains much variability which makes the task of ASR difficult. Variability includes intra-speaker (physical/emotional state, etc), inter-speaker (physiology, accent, etc), speaking style (read/spontaneous, formal/casual, etc) and in the acoustic channel (noise on the microphone, limited speech channels, etc).
ASR devices often lump together many oif the variability sources. An ASR system needs the means of dealing with (i.e., the capability to model) spectral variability (linear or non-linear effects due to all variability sources) and timing variability (mostly non-linear effects as speech can be stretched in a non-linear fashion, in addition to variations for speaker independent and continuous speech). The importance of these effects depends on the task.
Speech recognition tasks are typically constrained to limit the variability (e.g., by asking for isolated words, limiting the system vocabulary, constrained syntax and low noise conditions) and research currently focusses on making recognition systems more general - resulting in large vocabulary, speaker-independent, continuous speech recognition systems trained on data from a variety of different sources.
Classification
The recogniser capabilities can be defined along a number of dimensions: speech, environment, linguistic criteria, input/output forms, internal specifications and the recogniser platforms. For types of speech, classifications include the mode of speaking (e.g., isolated word, short phrases or continuous speech), the speaker set (single speaker (can be trained to be dependent), multi-speaker or any-speaker (must be speaker independent)). Most speaker independent systems make assumptions about accent subsets and a modern trend is towards speaker adaptive systems.
When considering environmental factors, noise is a key factor (whether the environment is noise-free, in an office or high-nouse) and whether this noise condition is fixed or adaptive. An additional factor is that of the microphone or channel (e.g., close-talking, far-field, telephone, etc).
Linguistic criteria can also be considered for classification of ASRs: their vocabulary (very small ≤ 20 words, small ≤ 200 words, medium ≤ 2000 words, large ≤64k words or very large > 64k words), their syntax (non-existant, finite-state, context-free - possibly stochastic - or n-gram) and the language domain (single language, multi-language, etc) they work in. Some ASRs also support multi-modal input, such as combined modelling of lip-reading, gesture or speaker identification.
Other classifications include that of system output, whether it gives multiple hypotheses (possibly ranked) or possible outputs, confidence scores for each word in the output or "rich transcripts", which are human readable. The internal representation of the system can also be considered - whether it stores representations of words or sub-words (phones), which are more flexible and allow for vocabulary independence.
What makes a "good" ASR system?
Low error rate is one common metric used. This compares the output of the output string with a manually transcribed version (reference transcript) and the word error rate is the percentage of words that were different.
Another common metric is user satisifaction. As recognisers form part of a larger system, users are more interested in the overall system performance rather than the raw error rate.
It is necessary to integrate the recogniser (and its shortcomings) into the design of a system so that it can cope with recognition errors (e.g., by using confirmatory dialogue and allowing correction).ASRs historically have worse performance in the field than the lab, hence the collection of realistic databases for development and test is necessary.
Statistical Speech Recognition
In ASR, our task can be reduced to finding the most likely sentence (word sequence) W used for generating the utterance A: W^ = maxWP(W|A). By Bayes rule, we can rearrange this to W^ = argmaxWP(A|W)P(W). In this model, we can consider P(A|W) to be the acoustic model and P(W) the langauge model. The ASR problem is then reduced to finding solutions for two problems: training (finding suitable representations for the acoustic model and the language model) and recognition (finding the most likely word sequence W^). The most common form for the acoustic model is a hidden Markov model (HMM), and for the language model, N-grams.
A generic ASR architecture typically consists of a speech processing front-end (providing A) and a vocabulary (providing W) along with the acoustic model (P(A|W)) and the language model (P(W)) all feeding into the search (argmax) which outputs the most likely word sequence. Often some feedback is introduced which alloes for adaptation of the langauge and acoustic models.
The front-end converts the audio into a stream of feature (observation) vectors. The acoustic model is responsible for matching acoustics and individual words as defined in the vocabulary and is the most complex part of an ASR system. The language model represents syntactic, semantic and discourse constraints on the output string (ensuring what is output is valid), and in some cases no (or a null) model is appropriate. Words not in the vocabulary can cause errors.
Isolated word recognition simplifies the system by pre-segmentation of the speech data, however this is not straightforward in anything but a low-noise audio environment.
Front-ends
By far the most common front-end is based on Mel-frequency Cepstral Co-efficients (MFCCs). Typically overlapping (one every 10 ms) speech frames of 25 ms length are used. This is done to capture changes of speech over time and 25 ms is a good number to capture the quasi-stationary property of speech - phones are typically between 50 and 200 ms in length, although more often towards the shorter end of this range. Overlapping is done to avoid discontinuities.
A Hamming window is applied to stop spectrum distortion in the FFT phase. FFTs assume that signals are periodic, and not applying a window can lead to sharp edges ("leakages") in the signal. A Mel filterbank is applied and then log conversion of the signal and a discrete cosine transform applied to arrive at a feature vector of the MFCCs. Normally the 0th cepstral coefficient is excluded, so a measure of raw energy needs to be added to the feature vector.
Mel-scale filterbanks use band analysis to model masking effects by the ear together with non-linear frequency and bandwidth allocation. The energy in each frequency band can be computed by DFT. Phase information can be disgarded as experimental results show that humans can not differentiate between identical sinusoids with different phases. The spacing of the centre frequencies is based on the Mel-scale, defined as: Mel(f) = 2595 log10(1 + f/700). This is often regarded as being approximately linear up to 1 kHz and then logarithmic thereafter.
Cepstral coefficients can be derived from the Mel filterbank energies using a simplified version of the DFT known as the discrete cosine transform (DCT), which takes advantage of the fact that the log magnitude spectrum is real-valued, symmetric with respect to 0 and periodic in frequency:
cn = √ ∑Pi=1micos((n(i - 1/2)π)/P), where P is the number of filterbank channels.
The DCT decorrelates the spectral coefficients and allows them to be modelled with diagonal Guassian distributions. The number of parameters needed to represent a frame of speech is reduced, in turn reducing memory and computation requirements. c0 is a measure of signal energy.
MFCCs describe the instantaneous speech signal spectrum, but take no account of signal dynamics. Moreover, the use of HMMs requires that dynamic information is packed into local vectors because of the assumption of frame independence. This situation can be improved by including rates of change of the coefficients (differentials) in the representation. Typically, regression coefficients are used to calculate the best straight line through a number of frames:
Rn(t) = (∑δτ=-δτcn(t + τ)) / (∑δτ=-δτ2)
For similar reasons, the representation can also be augmented to include the second differential of the static coefficients by again applying the regression formula to the first order differentials. For HMM-based speech recognisers, a modern standard representation includes static, Δ and ΔΔ coefficients.
Any fixed linear filter that is applied to the speech (such as a microphone) causes the measured speech spectrum Y(ω) to be the product of the original speech S(ω) and the frequency response of that particular filter H(ω): Y(ω) = S(ω)H(ω).
Taking the logarithm (which can only be done on a magnitude spectrum) allows us to express this as: log Y(ω) = log S(ω) + log H(ω), and log |Y(ω)| = log |S(ω)| + log |H(ω)|, which shows that the distortion of the speech signal is additive.
If log |H(ω)| can be estimated, it can be subtracted and the measured speech is then independent of the channel. This is derived from the idea that, within an additive constant, log |H(ω)| is the average value of log |Y(ω)| over the utterance (or set of utterances on the same channel), since it is assumed that on average log |S(ω)| is flat.
If yt represents a frame of observed speech in the spectral domain, hence st + ht, where ht is assumed to be constant over time, then:
1/T ∑Tt=1yt
= 1/T ∑Tt=1(st + ht)
= 1/T ∑Tt=1(st + h)
= Th/T ∑Tt=1st
= h
Since the cepstrum is a linear transformation of the log spectrum, as are MFCCs. For MFCCs, the average cepstrum (e.g., over an utterance) can be subtracted from all the static coefficients. This is termed cepstral mean normalisation (or subtraction or removal).
Pattern Processing
The acoustic model P(A|W) estimates the match between the acoustics A and the word sequence W. The front-end converts the acoustic signal into a sequence of feature vectors: A ≡ O = [o1, ..., oT] = oT1, where oi are the feature vectors. The number of feature vectors, T, extracted varies due to the length of the utterance, and for many applications are the 39-vectors MFCCs discussed above.
The probabilityy computed by the acoustic model can now be written as P(O|W) = P(o1, ..., oT|W), which can be interpreted as a distance between the sound and the word. However, such a distance is still complex and needs simplification.
Most speech technologies work in a similar way to speech recognition, which implies that some model is trained to map an acoustic signal to the target value of the classification task. In the case of gender recognition, an acoustic model is required to compute two probabilities: P(O|male) and P(O|female). The prior probabilities P(male) and P(female) are considered uniform.
Other methods for classification include a naive method, such as setting a threshold over which pitch is considered female and below which pitch is considered male, and then voting on the class based on the number above or below the threshold. More complex methods may involve decision rules to calculate average pitches for male and female speakers (determined by training data) and then classify a new sample based on the distance from the average of each sample point. This distance can be computed by some cost function (e.g., Euclidean distance) - which must be the same in both training and recognition.
The detection/recognition operation is then performed by comparing these probabilities and selecting the gender with the highest probability. Using the chain rule we can express P(O|male) as ∏Ti=1P(ot)|ot-11, male), and likewise for female - this tells us that modelling only looks at the past data, not any future points.
For training, we can use maximum likelihood to get the best model for known data. The aim is to find the minimum mean distance from all points for our cost function, this can be compouted using dC/dMF.
The chain rule allows us to split the probability term into a product of probabilities, one per frame, however for each frame we have the previous frames as conditional variables which can lead to intractable problems in many applications, thus we assume frame independence. This assumption is obviously false as a current F0 is related to the one before it, i.e., it is in the same region as one before it. Now if we take the logarithm can get our product in terms of sums, which shows a similarity to the distance metrics.
Distance Metrics
Distance metrics are used to compare a speech vector o with another speech vector v. A distance measure d(o, v) is defined such that it is large if o and v are different, and small is they are similar.
Euclidean
Euclidean distance is defined as dE(x, y) = √.
Euclidean distance is analogous to physical distance, and other related forms include squared Euclidean (dropping the square root), the maximum distance and the city-block/Manhatten distance.
Mahalanobis
The Mahalanobis distance is given by dM(x, μ) = (x - μ)'Σ-1(x - μ), where Σ is the covariance matrix of the data.
This is equal (within a constant independent of the vectors) to the negative log of the probability density of a vector x from a multivariate Gaussian distribution or mean μ and covariance Σ, and to the squared Euclidean distance in the case of Σ being the identity matrix.
For cepstral representations, any of the above distance measures are appropriate (since their distributions are close to Gaussian), however for LPC predictor coefficients, the Euclidean distance is not appropriate and often the Itakura distance is used.
Itakura
Given two different LP filters with the extended LP coefficient vectors a and b with the autocorrelation matrix R, the mean square error of the LP filter on some signal with the autocorrelation matrix R can be computed by E = a'Ra for each vector, instead of using Euclidean distance. If the difference in MSE is small, the filters are considered to be close.
The Itakura distance is defined as: dI = log(a'Ra/b'Rb).
Vector Quantisation
There are a number of instances where it is required to represent a continuously valued multi-dimensional vector by a discrete symbol. This process is called vector quantisation (VQ). This speech vector o is mapped to a scalar: o → k. A codebook C is then built up as a set of K centroid vectors (codewords, or representative values). The observation vectors are then mapped to a codebook symbol using k = argmin1≤l≤Kd(o, vt).
The set of codewords together with a distance metric provide partitioning of the space.
Linde-Buzo-Gray (LBG) algorithm
The Linde-Buzo-Gray algorithm, otherwise known as the generalised Lloyd algorithm or k-means clustering, are commonly used to train VQ codebooks.
The algorithm is initialised by choosing an arbitrary set of K codebook vectors {v1, v2, vk}. Then, for each speech frame ot in the training data, the codeword/classification q is calculated: kt = argmin1≤l≤K d(ot, vt), where d(ot, vt) is some sort of distance measure. The total distortion D = ∑td(ot, vkt) is computed, and if D is sufficiently small, then the process stops. If not, all the codebook elements are recomputed from the assigned observations (means are sampled) and the process repeats.
This clustering procedure may produce empty means, and has been shown to converge to a local maximum, so it is best to do multiple runs.
Centroid Splitting
Alternative algorithms exist which do not require a start from a predefined number of clusters. One such method is to start with 1 centroid and split when distortion is below some cutoff value, until a maximum is reached. It is important to set this maximum correctly - if too many centroids exist (such as one per example), then the model can overfit the training data.
For classification, the distance to the nearest codebook values are summed up and the classification with the smallest distance is used.
Gaussian models
The Gaussian distribution is one of the most important probability distributions: P(x) = 1/σ√ e-(x - μ)2/2σ2, where σ2 is the variance and μ is the mean.
To give a score, two Gaussian models are learnt - one for male and one for female. The probabilities of P(O|male) and P(O|female) are then compared, where P(O|male) = ∏tP(ot|M), and similar for female, where these probabilities are drawn from the Gaussian distribution.
To learn these example parameters, then μ = 1/T ∑tot and σ = 1/T ∑t(ot - &mu)2.
Warping
A simple detection approach to classify utterances is to compute the average distance of all feature vectors in the observation to a reference vector vj for a particular word wj. The word wk with the minimal average distance is then selected. If we extend the concept to use a reference template of length T instead of a reference vector, then if the length is identical, to the observation we can compare the vectors one by one.
However, the length of the template is fixed and the length of the observation sequence varies, causing an alignment problem. When varying the length of speech, it is only some phones that change in length, not all phones linearly, therefore linear warping is inappropriate here, and non-linear warping is needed.
Dynamic time warping is a technique such that the total difference between two sets of vectors is minimal, and it can be implemented efficiently by the use of dynamic programming.
First order Markov chains
A Markov chain is a stochastic process based on state machines that can generate a random sequence that is discrete in time and value. The output of the process is a sequence of length T given by X = [x(1), x(2), ..., x(T)], such that the values x(t) are taken from some finite alphabet S = {s1, s2, ..., sM}, representing the states the Markov model moves through.
Using Bayes, the probability of the output sequence can be computed: P(X) = P(x(1))∏Tt=1P(x(t)|x(1), ..., x(t - 1)). A first-order Markov chain makes use of the independence assumption that the probability of a particular symbol at a particular time, x(t) only depends on the immediately previous symbol, x(t-1) - the Markov assumption. Hence, P(x(t)|x(1), ..., x(t - 1)) = P(x(t)|x(t - 1)).
In a first-order Markov chain, the probability of a sequence X is defined by P(X) = P(x(1))∏Tt=1P(x(t)|x(t - 1)), where P(x(1)) is the initial probability of the sequence and the other probabilities are transition probabilities.
The set of initial probabilities is defined as: ∀1≤i≤M πi = P(si), such that ∑Mi=1P(si) = 1, i.e., the sum-to-one condition. We can have a single initial state by simply setting this πinitial = 1.0.
The transition probabilities are defined as: ∀1≤i≤M, 1≤j≤M ai,j = P(xt = si|xt-1 = sj), such that ∑Mi=1P(si|sj), 1≤j≤M, i.e., the probabilities of leaving a node must sum-to-one.
The sets of initial probabilities and transitional probabilities complete define the Markov chain. These parameters are constant (not a function of time) and therefore this process is stationary.
The alphabet defines the states, and the random sequence is generated by moving from one state to another state, with the state selections governed by the transition probabilities.
To learn the probabilities of a Markov chain, this is straight forward. To discover the initial probabilities, we look at the training sequences and then look at the frequencies of a state starting a sequence over the total number of examples. For transition probabilities, transition pairs in sequences are considered and the probabilities computed such that ai,j = N(i→j)/N(j), that is, the frequency of that particular transition divided by the frequency of i.
Hidden Markov Models
In the case of Markov chains, the state sequence is identical to the observation sequence - each state produces a symbol which is uniquely associated with that state. Hidden Markov models can be viewed as an extension to Markov chains where the output ot of a state j at time t is governed by some probability distribution called the output distribution.
A Markov model is "hidden" as the state sequence is hidden by not being directly mapped to the data, but instead mapped by the output distribution.
bj(ot) = P(ot|x(t) = j), is used to represent this output distribution. The output distributions can be discrete, which usually requires quantisation of the feature stream O by the use of a vector quantiser. This observation data is filtered through a codebook kt = Q(ot), and bj(ot) = P(kt|x(t) = j).
Output distributions can also be continuous, and is typically represented by a Gaussian, and the probability replaced by a probability distribution function. Other distributions can indlude Laplacians, mixtures of Gaussians, etc.
For speech, as HMMs output some state alphabet, not spectrogram vectors, output distributions are needed. We could associate states with codebooks, but there is no guarantee that always the same vector is used (so it is not discrete). Gaussian distributions are used instead. Speech signals consist of quasi-stationary segments of finite length can be reasonably well described by concatenation of small sound units (phones). Left-to-right HMMs can be used to model these properties. In a left-to-right HMM, each state can produce an infinite number of output symbols, before moving on to the next one (and no moving back, hence left-to-right). The initial and final state of the HMM is non-emitting.
HMMs generate random, stationary sequences. The procedure to generate a random sequence is:
- Select an initial state according to the initial probabilities;
- If the current state is emitting, generate an output symbol according to the output distribution of the current state;
- Select the next state according to the transition probabilities from the current state, then move to the next state;
- If the current state is emitting and has transititons other than to itself, repeat step 2.
Isolated Word Recognition
If words are spoken in isolation, we can reduce the complexity of the search for the best word sequence. We assume that words are separated from each other (in a sentence) by detectable pauses. The task for the acoustic model is simplified to providing an estimation of probabilities for words individually.
The front-end produces a stream of feature (or observation) vectors: O = [o1, ..., ot, ..., oT]. In continuous ASR, we have to search for the best word sequence W^ = argmaxWP(O|W)P(W), however if the audio stream can be separated by segmentation of the audio signal (so called end point detection) into M segments Oi where i = 1..M, the sentence length (number of words) is directly derived from the audio signal.
Each audio stream Oi is associated with one particular word out of a sequence W = [w1, w2, ..., wi, ..., wM] where the acoustic realisation of one word can be assumed to be independent of the neighbouring words. Thus, we can simplify the formula for continuous ASR to: W^ = argmaxWP(W)∏Mi=1P(Oi|wi).
If words are assumed to be completely independent, we speak of word classification. Using a vocabulary of size N, we can choose the index of the likely word k = argmax1≤i≤NP(O|wi)P(wi), where each word is really a hidden Markov model. This allows a linear search for the best matching model. If all words are equally likely (i.e., P is a uniform distribution), then we pick the word w with the highest likelihood P(O|w).
Using Gaussian PDFs for the output distribution, we can define an HMM by the transition probabilities ai,j, which implicitly define the topology of the HMM, the mean vectors μi and the covariance matrices Σi, although typically only the diagonal covariance matrices are used (resulting in uncorrelated vector elements). These form a multi-variate Gaussian distribution.
If we can compute the likelihood of an observation sequence, we can use the earlier equation to select the most likely word. Models for each word in the vocabulary are needed, and this model is represented by the model parameters λw = {{ai,j}, μi, Σi}, and the N word models make up the parameter set of the acoustic model: λ = {λw1, λw2, ..., λwN}.
The use of HMMs for ASR raises a number of questions: how to compute the probability of a given observation sequence O and a certain word w - P(O|λw), which is required for comparing word hypotheses in classification; what the most likely sequence that produced a given observation sequence is, knowledge of which allows timing information to be assigned to the audio stream which can be used for segmentation of speech data, as a simplified training scheme for HMM (as knowing a mapping of vectors to states makes this very easy) and for decoding; and how are the model parameters are chosen.
For choosing the model parameters, the parameters which achieve maximum likelihood over some training data is achieved (maximum likelihood estimation - MLE).
If the HMM parameter λw, the state sequence (or path) X and the observation sequence O are known, the likelihood for the joint event can be expressed in terms of output probabilities and transitions: P(O, X|λw) = P(O|X,λw)P(X|λw).
The probability of the state sequence is similar to Markov chains. Assuming that the initial (x(0)) and final (x(T + 1)) states are non-emitting: P(X|λw) = P(x(1)|x(0))∏Tt=1P(x(t + 1)|x(t))
The likelihood of the observation sequence O given the state sequence is then: P(O|X,λw) = ∏Tt=1P(ot|ot-1, ..., o1, x(t)). However, as each observation is independent from the others, given the current state, then we can simplify this as: P(O|X,λw) = ∏Tt=1P(ot|x(t)).
The total likelihood of the feature vector stream O, given the model for a particular word λw = ∑XP(O, X|λw), or using Bayes: ∑XP(O|X,λw)P(X|λw), where ∑X denotes the summation over all possible state sequences.
This definition of HMMs is based on independence assumptions: the Markov assumption (the probability of a transition into state j from state i is independent of previous states) and conditional independence (given a particular state at time t, the likelihood of the output symbol at that time is independent of any other state or previous output symbols).
However, these assumptions are problematic for the modelling of speech, since we expect smooth paramater trajectories, showing a strong correlation over time.
If both the state sequence and the observation sequences are known, a clear connection between any symbol in the vector stream and a state can be established. The feature vector stream also carries implicit informaation about time (e.g., one vector per 10ms). Ideally, all vectors associated with one state should belong to the quasi-stationary part of the speech signal, which allows the signal to be segmented in time. However, the state sequence is unknown (by the nature of a hidden Markov model), and one can not derive the original sequence with certainty, but given an HMM λw and an observation sequence O, the state sequence X* with the highest likelihood can be computed: X* = argmaxXP(O, X|λw), where the likelihood is given by:
P(O, X*|λw) = ax*(0),x*(1)∏Tt=1ax*(t),x*(t+1)bx*(t)(ot).
ax*(0),x*(1) is the initial probability, ax*(t),x*(t+1) is the transition probability and bx*(t)(ot) is the output probability.
P(O, X*|λw) can serve as an approximation to the total likelihood. In this case, all other paths (competing state sequences) are assumed to provide only a minor contribution to the total likelihood.
The knowledge about the best state sequence allows us to temporally segment speech. This can be used to segment words into smaller units, sentences into whole words, or to enable a simplified training procedure of HMM parameters.
Trellis
The trellis is another option to visualise the operation of an HMM. This provides us with a joint visualisation with the observation vectors over time, allowing us to plot the path through the HMM.
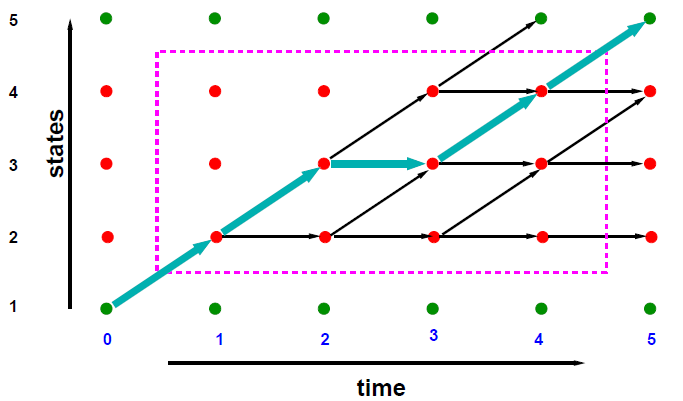
The most likely path through the trellis is depicted with the bold arrows, and the likelihood can be computed by the multiplication of the transitition probabilities (the arcs) with the output probabilities (the nodes). The non-bold arrows on the trellis indicate all allowed transitions.
The Viterbi algorithm
The Viterbi algorithm is a dynamic programming procedure to obtain the most likely path for a given model λ and observation sequence O of length T.
First, we define the likelihood of a partial path of length t, which ends in state j: &Phij(t) = P(o1, ..., ot, x(1), ..., x(t - 1), j|λ)
Then, the likelihood of the partial path can be expressed in terms of the likelihood of the preceeding state x(t - 1): &Phij(t) = ax(t - 1),jbj(ot)Φx(t - 1)(t - 1)
We can assume that our algorithm starts in the final state, as this state must be on the optimal path X*. We can now use the equation above to express the joint likelihood &PhiN(T + 1) = P(O, X*|λ) in terms of the previous state: &PhiN(T + 1) = ax(T),N&Phix(T)(T).
Multiple paths may lead to the final state, however the optimal path is defined as the one which achieves the highest likelihood value P(O, X*|λ), thus one can select the preceeding state x*(T) such that &PhiN(T + 1) is maximal: x*(T) = argmax1≤j≤N(ajN&Phij(T))
For simplicity, we use the notation k = x*(T). Once the state at time T is known, the partial likelihood Φk(T) can be expressed in terms of the predecessor state: Φk(T) = ax(T - 1),kbk(oT)Φx(T - 1)(T - 1)
This includes the value for the output distribution at time T, so we again pick the preceding state that maximises Φk(t): x*(T - 1) = argmax1≤j≤N(aj,kbk(oT)Φx(T - 1)(T - 1))
This procedure can then be repeated for x*(T - 2), etc. In order to operate in this manner, the values for partial paths (Φj(t)) need to be precomputed. This leads to a forward pass, followed by a trace-back.
If we assume that an HMM M has N states, but the states 1 and N are the non-emitting entry and exit states, then the steps to obtain the most likely path X* and the associated likelihood are:
Φ1(0) = 1.0
Φj(0) = 0.0 for 1≤j≤N
Φ1(t) = 0.0 for 1≤t≤T
until P(O, X*|λ) = max1≤k≤NΦk(T)akN:
for t = 1..T:
for j = 2..N-1:
compute &Phij(t) = max1≤k≤N(Φk(t - 1)akj)bj(ot)
store the predecessor node predk(t)
The most likely path can then be recovered by tracing back using the predecessor information stored at each node in predk(t).
The Viterbi algorithm has the important property of being efficient, as decisions are local, paths merge and divide at roughly the same rate, and the time for the search is linear in the length of the observed data T.
One concern is that the direct calculation of likelihood will cause arithmetic underflow, this practical implementations of the algorithm uses the computation of log(P(O, X*|λ)): Φj(t) = max1≤k<N[ log(Φk(t - 1)) + log(akj ] + log(bj(ot))
In this form, the search for the best state sequence appears as a generalisation of the template matching procedures used in dynamic time warping (DTW). DTW templates only represent a strict left-to-right topology, therefore in DTW the number of frames in the template is equal to the number of states, and all non-zero transition probabilities are equal.
We must also consider how to train a HMM. In training, we aim to estimate all the HMM parameters λ = {{ai,j}, {μj, Σj}}
These parameters can be estimated from training data consisiting of a set of R utterances Or for the word w represented by λ. A training algorithm should aim to produce the parameters which maximise the likelihood of producing the training data. We define the likelihood of a set of utterances as ∏Rr=1P(Or|λ).
A solution which guarantees the global maximum is unknown, however two iterative procedures for ML estimation of HMM parameters exist: Viterbi training, and Baum-Welsh re-estimation.
Viterbi Training
In the case of a Markov chain, the knowledge about the state sequence allows us to compute maximum likelihood estimates for the transitition probabilities as discussed above, however for HMMs, the state sequence is unknown. Knowledge about the most likely state sequence X* allows us to approximate the total likelihood: P(O|λ) ≡ P(O, X*|λ). The knowledge of the state sequence X* clearly assigns each observation vector to exactly one emitting state.
Due to the conditional independence assumption, the parameters of each output distribution can be estimated independently using the data vectors assigned to a state. Formally, we can use an indicator variable δ to show if the observation vector at time t, ot is associated with a state j: δ(x*(t) = j) = { 1 if x*(t) = j; 0 otherwise
See slide 20, handout 3
for the full formula.
This allows us to form an expression for the mean vectors and covariance matrices of the Gaussian output distribution for all states.
Another way of visualising δ is to consider the trellis as a matrix, with nodes on the most likely path given a value of 1, and others 0. Representing δ in this way allows for easy computation for the mean vectors and covariance matrices.
Baum-Welsh re-estimation
Viterbi training avoids the problem of hidden state sequences by use of the segmentation provided by the most likely state sequence, however the indicator variable δ represents a hard decision that the observation ot is produced by the state j.
Baum-Welch re-estimation takes the uncertainty about the state sequence into account. The indicator variable is replaced by the state posterior probability: Lj(t) = P(x(t) = j|O, λ)
This can also be represented as a trellis, but instead of 1s and 0s, the number at a node represents the probability of being in that state j at time t in some Markov model λ given some observation sequence O. Total probability applies, so for a time t, the probabilities of being in a given state must sum to 1.
Any observation vector may occur with a certain probability at any time. The forward/backward algorithm is needed to provide an estimate for Lj(t). Similarly, the estimation of transition probabilities provides an estimate for P(x(t) = i, x(t + 1) = j|O,λ)
Forward algorithm
The forward algorithm allows us to efficiently compute the total likelihood P(O, λ).
First, we define the forward variable αj(t) = P(o1, ..., ot, x(t) = j|λ), and then a summation over all states at a time t gives the total likelihood of the observation sequence up to time t: P(o1, ..., ot|λ) = ∑Nj=1αj(t)
The likelihood of arriving in a state j after t observations can be expressed in terms of the likelihood of being in state k at time t-1 (i.e., ot-1 is produced by state k): P(o1, ..., ot, x(t - 1) = k, x(t) = j|λ) = αk(t - 1)ak,jbj(ot)
A summation over all the states at time t-1 allows us to recursively compute αj(t): αj(t) = P(o1, ..., ot, x(t - 1) = k, x(t) = j|λ)
Given a HMM with non-emitting entry and exit states 1 and N, we can define the forward algorithm as:
α1(0) = 1.0
αj(0) = 0 for 1<j≤N
until P(O|λ) = ∑N-1k=2αk(T)akN
for t = 1..T
for j = 2..N-1
αj(t) = bj(ot)[∑N-1k=1αk(t - 1)ak,j]
In order to compute Lj(t), it is necessary to define the backwards variable: βj(t) = P(ot+1, ot+2, ..., oT|x(t) = j, λ).
The definitions of the forward and abckward variables are not symmetric. Given both variables for a certain state j at time t: P(x(t)) = j, O|λ) = αj(t)βj(t).
See slide 27 of handout 3
for the full formulae
Using this information, an N-state HMM (with states 1 and N being non-emitting) and a Gaussian output distribution can be re-estimated using the update formulae. Multiple iterations of estimating the parameters are required.
The magnitude of αi(t) decreases at each time step. This effect is dramatic in HMMs for ASR as the average values for bi(t) are very small and leads to computational underflow. Two approaches have been used to solve this problem.
One approach is to scale αj(t) at each time step so that ∑N-1j=1αj(t) = 1. The product of the scale factors can then be used to calculate P(O|λ). Since this underflows, log P(O|λ) is found as the sum of the logs of the scale factors.
An alternative solution is to use a logarithmic representation of αi(t). Many practical HMM systems use this solution.
When training HMMs, the model topology (the number of states and connectivity) must be defined before training commences, and an initial estimate of parameters is required. Uniform segmentation of data is often used to get the initial values (this is the same as setting all the parameters equal). Additionally, the update formulae need to be applied repeatedly until the likelihood of the training data converges. All calculations required the use of log arithmetic, or scaling.
However, we still have two issues with using Gaussian models and HMMs for speech recognition: the features extracted from the speech signal are multi-dimensional; the models assume that the feature values are distributed with the normal (Gaussian) distribution, and in order to achieve good performance, both issues need to be addressed.
Multivariate Gaussian distributions
A straight-forward solution to the multi-dimensionality issue is to assume independence between the dimensions of the feature vector. If the feature vector with dimensionality D is used, then the independence assumption means: pD - dim(o) = ∏Dd=1p1-dim(od), that is, the probability density function of the vector is the product of the probability density function values of the vector elements. In most cases, we would assume that each dimension is a one-dimensional Gaussian distribution.
Slide 5 of handout 4
contains the MLE for multivariate
Gaussian parameters.
Multivariate Gaussian distributions can also be used. These are typically visualised by plotting the first 2 dimensions of a Gaussian, and then showing higher dimensions by plotting contour lines of equal probability on this plot.
Now, when training the elements, for the covariance matrix Σ we only consider elements on the main diagonal, which represent σ2. Elements off this main diagonal are called the covariance terms, and if they are 0, then we consider the elements on the diagonal to be statistically independent.
As MFCCs make dimensions independent of each other, we can make this independence assumption and consider each dimension to have an independent Gaussian for training.
Gaussian Mixture Models
Even though one can strive to extract feature vectors that are nearly distributed by Gaussian, in many cases this is not realistic. Instead, we assume a more general form multi-modal distribution.
Centroid splitting (as discussed above) can be used to create multiple Gaussians that represent the data, but we need a single model: P(ot) = ∑P(ot|μi, Σi)
However, this distribution is continuous, and our sum-to-one constraint still applies, so we have the restriction of ∫∞-∞P(ot) dt = 1
This restriction causes many difficulties, so instead we introduce weights on the parameters which must sum-to-one. This is called a Gaussian Mixture Model: P(o) = ∑Mi=1wiP(o|μi, Σ), where M is the number of mixture components and wi are the component weights.
We therefore have M mean vectors, M covariance matrices and M mixture weights. This can be interpreted as a Hidden Markov model with M states in parallel, where the transition probabilities are the weights, and the output distributions are standard Gaussians.
Continuous Speech Recognition
Isolated word recognition simplies the ASR architecture by pre-segmentation of the speech data. However, this is not straightforward in anything but a low-noise environment.
For isolated word recognition, we can use the Viterbi algorithm to find the likelihood, along with the optimal state sequence, that the HMM generated an unknown utterance observation. This same algorithm can be used for continuous recognition.
For the isolated word case, we can construct a composite model by joining all the start states and all the end states of all the possible word models together. For isolated word recognition, we then find the optimal state sequence through the composite model, and hence find the single word model that was most likely to have generated the input speech.
For isolated word recognition, we used models for words. In order to deal with continuous speech, we need to use models for phrases. Conceptually, we need to construct all possible word-model sequences, recognise the input using each constructed model sequence, and select the highest probability sequence as the recognised word string.
In general, neither the order, nor the number of words in the input is known. This gives a large number of possible sequences for even a relatively small vocabulary. Due to the explosion in combinations, we can not explicitly perform the computational concepts outlined above directly, however phrase models do still form the basis of our solution. A solution can be derived by extending the model used for isolated word recognition.
For continuous speech, when each word can follow any other with equal probability (uniform language model), the generator composite model is the same as before, but with the start and end states connected.
For continuous recognition, the optimal state sequence, and hence the optimal word sequence, can be found for this composite model using the Viterbi algorithm. If the state sequence is not required, to recover the identity of the component words, only the points where transitions cross the end state of a model need to be recorded.
The selection of a suitable vocabulary depends on the task. Recognition of isolated words usually only requiries the handling of a small vocabulary with few words. A word in this context may be any utterance, e.g., a full name for a mobile phone system.
The vocabulary required for transcription tasks is usually derived from large amounts of text, typically in the order of tens of millions of words, however the amount of data available for training the acoustic models is much smaller (100 hours of speech is roughly 1.2 million words, but often less than this is available). Often, all inflected forms are also included in a dictionary.
For the purpose of large vocabulary speech recognition, the use of HMMs is inpractical due to the sparseness of training data, the introduction of new words, and designing the topology of the HMMs.
Often sub-word units are used to build the HMMs. Possible sub-word units include phones, of which there are 40-50 in English, but there are also allophones, with considerable variability and context dependence, and non-unique mapping from phones to words (homophones). Phones are well-defined, however. Syllables are another sub-word unit that has recently attracted more interest, however there are other 10,000 syllables in English, they are ill-defined, and automatic syllabification is difficult.
Due to the ability of HMMs to be composed together to construct larger HMMs, and the use of unique entry and exit states, HMMs can simply be concatenated to allow the construction of words from sub-word units, and of sentence models. Probabilities can be assigned to the transitions between HMMs, however the power of HMMs is not in the transition probabilities, but in the Gaussians.
Lexicons, or recognition dictionaries, provide the translation between words (the unit of interest in recognition) and speech units. Isolated word recognition often has a trivial form of one-to-one mapping, but in the use of composed phone HMMs, the pronunciation of each word can be described by phonetic transcription, with each phoneme being represented by a particular HMM.
The type of dictionary is a simple case of a pronunciation model. In many cases, the dictionary is hand-crafted by a human expert, and when the HMM for each phoneme is available, a word HMM can be constructed by concatenation.
Acoustic Modelling
For acoustic modelling, we must consider the acoustic units we are going to use. From a classification point of view, we can assign units a number of properties:
- compact - ideally, the number of parameters in the set of models should be independent of the vocabulary size, task complexity, etc;
- representative - the model for a unit should, in theory, be able to capture unit specific variation only, and these units need to be defined accordingly;
- clear relationship to words - the relationship to words should be well-defined (i.e., clear mappings that allow, for example, the cosntruction of models for unseen words);
- distinctive - units should be well distinguishable from each other (discriminative);
- clear topology - the model topology (the number of states and the transitions), should be easily definable, which each unit having the same topology (however this is difficult, as syllables and words have a variable length).
Using this criteria, we can compare word and phone models. For word models, the number of models increases linearly with the number of words, whereas for phone they're constant. Word models can implicitly capture all variation in terms of pronunciation, which phone models do not capture. For word mapping, in the word model this is a trivial, but new words need to be trained, whereas in the phone model, word mapping is achieved through a dictionary. Word models are distinctive as they are exactly the classes that we want to separate, whereas monophones are broad classes that overlap highly in acoustic space. The topology for word models is to be determined heuristically, but for phone models a standard fixed number of states is sufficient, although some tuning can be useful.
The number of free model parameters necessary for representing the acoustic model is of great importance, and for word models, the number of parameters is linear with the number of words, whereas for phone models, it is a function of the number of phones.
Unit selection is driven by the requirement that the units should be trainable, i.e., that sufficient data for each unit is available, and implicitly, the number of units defines the number of parameters present in a model.
The number of parameters needs to be optimised to yield optimal performance, however we must be careful to avoid overfitting the parameters the training data. The optimal number of models and free parameters are training set dependent.
Context-dependent phone models
Coarticulation means that the actual sound associated with a particular phoneme depends on the neighbouring sounds (in a word or sentence context). For an utterance which has the same phone, spectrograms differ substantially for each realisation of that phone. To handle this problem, context-dependent phone models have to be used.
Models for single phones are context-independent and are called monophones. Models which take the phonemic neighbours into account are called context-dependent, and the models associated with one phoneme are called allophones.
Several types of models with varying context depth exist: monophone, left biphones (a model of the phone considering only the phone immediately before it), right biphones (as left, but only considering the phone immediately after it as affecting coarticulation), triphones (considering both sides) and pentaphones (2 neighbours). In all cases, the dictionary still only needs to have the monophone representation, and the conversion into triphone names is performed automatically. Triphones are the most commonly used models, however it is important to realise that not all triphones exist in practice (z-z+z).
However, we have an issue as the number of potential phone models grows exponentially with the context depth: for monophones, 46 models are needed, for biphones, 2116 and for triphones, 97,336. This large number causes 2 issues: insufficient data for training an individual triphone model is observed in the training data; and the training and test dictionaries differ normally, so unseen triphones are those that would be required for recognition, but are not present in the training data.
One way of limiting the number of models required is by using word-internal triphones (that is triphones that cross word boundaries are not considered), instead of crossword triphones.
Word-internal triphones make use of lower order models, and thus have the advantage of much smaller amounts of distinct contexts. However, it does result in poor modelling of very short words, which are normally frequent - furthermore, in continuous speech, normally there are no pauses, and hence coarticulation occurs across word boundaries. The added cost for search is fairly low, with this model, however.
To deal with the problems identified above, strategies need to be found.
Backoff
The simplest strategy to deal with the second issue is to back off to models have been observed in the training data, and thus could not be trained.
- Search for the triphone X-Y+Z in the model set;
- If not available, search for Y+Z or X-Y;
- If both are not available, use the monophone model Y.
This strategy is called model back-off. For discrete HMMs, sometimes a variant called interpolation is used.
Clustering
The first problem can only be controlled by defining units for which sufficient data is available. This can be done by grouping several triphones together to form clusters.
Two clustering strategies are commonly used: clustering by rule, where groups of triphones are formed on the basis of manually generated rules, and data-driven clustering, where the clusters are formed automatically by the optimisation of some distance criterion.
Data driven clustering is by far the better choice as it allows automatic adjustment of the model set sizes to the properties of the training data (small number of clusters for small amounts of data, large numbers for large amounts of data). Clusters do not have to be of equal size.
There are two types of clustering: bottom-up and top-down.
Bottom-up, or agglomerative, clustering requires that first, all triphone models are trained in the standard fashion. Then, the following steps are taken:
- Compute the distance of all triphones to each other;
- Merge the two triphones that are the closest;
- Repeat the procedure until the distance between the two closest triphones exceeds some threshold.
This tying/clustering of models is not necessarily restricted to complete triphone HMMs (generalised triphones), and it turns out that the clustering is much more powerful, yielding better results, if performed on the state level. This means that only the output probability distributions (GMMs) are clustered.
For clustering, we need to define some distance metric (i.e., a measure of how different a pair of triphone models really is). In practice, the definition of such a distance metric is difficult, and likelihood based distance measures are typical: d(M1, M2) = 1/T1(log(p(O1|M1)) - log(p(O1|M2))), where M1,2 denotes models, O1 is a sequence of T1 vectors generated by a model M1.
For the simplified case of 2 single Gaussian models, this turns into the so called Kullback-Leibler distance: d(M1, M2) = 1/2(tr(Σ-12Σ1 - I)) + (μ1 - μ2) + log(|Σ1|/|Σ2|).
A symmetric version of the above formula is given by: d′(M1, M2) = (d(M1, M2) + d(M2, M1))/2
A top-down method of clustering exists called phonetic decision trees, where binary decision trees are built based on phonetic questions about neighbouring phonemes. In contrast to agglomerative clustering, this allows both problems to be solved: there is no need for backoff, as unseen contexts are handled seamlessly, expert knowledge is incorporated in the form of questions and we are allowed (in theory) to incorporate arbitrary contexts. These phonetic decision trees are scale to the amount of training data, and are usable for both HMMs and individual states. It is standard to use phonetic decision trees on a state-level in conjunction with a likelihood criterion formulated on the basis of the training data.
At each stage in the top-down clustering procedure, each question out of a predefined (manually generated) set is tested - each question can split a set of triphones into two parts. If sufficient likelihood gain is obtained by the split, the question is added to the tree, and the process repeated.
To train these new sub-word models, we have a straightforward extension from the training of continuous speech whole-word HMMs. Each training set consists of pairs of audio signals together with word level transcripts. Before standard Baum-Welch training can resume, the appropriate sentence models need to be constructed.
In whole-word models, each word is replaced by the appropriate left-to-right model for each word, and all of these models concatenated. In monophone models, each word is first replaced by the string of phones, and then by the models for each phoneme. For state-clustered triphone models, each word is first replaced by a string of phones, then the phones are converted into triphones. Finally, for each triphone state, the appropriate output distribution is found by used of a phonetic decision tree.
Language Modelling
For a generic speech recognition system, we normally try to find the word string W that maximises P(W|O) (which by Bayes rule is p(O|W)P(W)), where O is the observed acoustic data.
Language modelling concerns the models used to estimate P(W). This overall string probability can be decomposed into word-by-word probabilities of partial strings given a history. First, sentence start and end markers are added to each sentence, such that w0 and wk+1 are the locations of the sentence start and end markers respectively. The probability of a K word sentence W = w1...wk can be computed by P(W) = ∏K+1k=1P(wk|w0...wk-1).
If the search is to be performed from left-to-right through the utterance, a decomposition of P(W) is required so that the language model allows the prediction of the next word wk in the sequence from the current history. Therefore, language models for recognition should admit this decomposition and if they are to be used directly during search, they are required to be predictive. The use of the sentence end marker allows the end of the sentence to be predicted.
These word-by-word conditional probabilities can be used to set the word-to-word transition probabilities in a network encoding the set of allowed sentences (often all word sequences) and are used directly in search to find the most likely word sequences.
Some common language models include n-grams, stochastic decision trees, Markov sources and stochastic CFGs. These differ in overall structure, the types of history are viewed as equivalent, whether or not they can be easily factored, and how the parameters of the models are estimated. All of these are static language models (i.e., the probabilities don't change with topic or context), therefore a number of adaptive langague modelling components have been proposed.
The standard approach is n-grams, which is discussed in detail in COM6791.
The language model must be able to accurately compute the probability of the next word in a sentence given an arbitrary history, and this LM needs to be tranied on a large corpus to accurately model this. As a result, LMs need to generalise to unseen sequences and estimate suitable probabilities for them - this is the key issue of handling data sparsity while maintaining accurate word predictions.
Another important issue is lexical coverage. For any LM for speech recognition, we can not assume a closed vocabulary, so we wish to minimise the number of out-of-vocabulary (OOV) words. In order to train language models, each word has to occurr sufficiently often in the training data. Higher lexical coverage at a particular vocabulary size can be obtained if vocabulary is tailored for a particular individual or topic.
Most work on language modelling and speech recognition in general has been done using English and views the basic units as words (i.e., sequences of characters delimited by white space or punctuation), however some languages have rather different properties as far as language modelling is concerned (e.g., German allows widespread compounding, and some languages are highly inflected).
This leads to two problems if word modelling is used - increased data sparsity for estimating parameters for the language model, and a requirement for a recogniser that can handle many words.
Entropy and perplexity is often used to evaluate a language model, and is also covered in detail in COM6791.
Search
So far, we have discussed more precise information about the knowledge sources that are required for speech recognition. Clustered triphones have been shown to be the standard for acoustic models, and n-grams for language models. We then need to search for the best word sequence given the observed signal, using all knowledge sources simultaneously.
Search algorithms are sometimes called decoders ("decoding" the signals into text). Different search algorithms can be classified in different ways, but we consider the following qualities as desirable for our speech decoder:
- Efficiency - the compuational resources required by the decoder must be reasonable given the task - "faster than real-time" performance is often required;
- Accuracy - the decoder should always find the word sequences given the knowledge sources. This is not identical to getting the correct sequence of words. Deviances from the best word sequence (as informed by the language and acoustic models) are called search errors;
- Scalabability - how the decoder handles arbitrary vocabulary;
- Versatility - ideally the decoder should be able to handle a large variety of knowledge sources;
- Flexible output - as well as the "best" word sequence, the decode should also be able to able to include alternative results (perhaps with some probability associated with it).
We have seen above how we can modify Viterbi for continuous speech, but the process identified above uses a uniform language model, and does not incorporate language models or state-of-the-art acoustic modelling techniques.
The recursion of the composite HMM results in a very large matrix for Viterbi. The Viterbi algorithm allows time-synchronous operation, and an efficient implementation of Viterbi that solves this large matrix problem is called token-passing.
Token Passing
In the Viterbi algorithm for a single HMM with N states, then in order to retain the best state sequence, pointers to a predecessor have to be stored - the back-trace informaion. the process of recovering the best state sequence is called trace-back.
For decoding, it is not necessary to store back-trace information for every state, if a full state alignment is never required. Instead, all that needs to be recorded is the the start time of the current model.
Each state of the composite HMM therefore holds one token, q, with two components: qj.prob - the log likelihood (i.e., Φj(t)); and qj.wlink - a pointer to the complete word history (all preceding words and their start times).
To implement this, we first set qj.prob to 0 in state 1 of every model, and qj.prob to -∞ (i.e., log 0) in all other states. Then inside:
for each frame:
for each model:
for each model state:
do word internal token propagation (that is, tokens move inside the component HMMs)
find the best exit token
do exit token propagation.
For word internal token propagation, the predecessor state i in model m is found for which qi.prob + log(aij) is maximum, and copy that token into state j, incrementing qj.prob by log(aij) + log(bj(ot)). The best exit token is determined in a similar fashion.
The propagation of tokens must be done simultaneously, and on completion, the model holding the token with the highest likelihood in state N identifies the unknown speech.
This token passing approach extends naturally to the continuous model case by extending the algorithm to identify the best token in the final states of all models, and allow the best token to propagate around the loop into state 1 of all connected models. The identity of the model which generated that token and its history are stored in word link records (WLRs), which are organised into a linked list.
These WLRs have 3 attributes: q, which is a copy of the q present in the final node; time, which is the current time; word, which is the word associated with that WLR; and a back pointer.
To propogate the exit token, the token with the highest probability is selected, a new WLR created and added to the linked list, and then the token updated with the new start time, and a constant 'P' added to the probability. This updated token is then copied into state 1 of all models.
The constant P is an inter-model log transition probability which forms an insertion penalty. It can be independently adjusted to control the rate of insertion errors.
At each time t, a new WLR is generated, and the complete set of WLRs represents the back trace information for recognition. Each WLR is created when a decision between words had to be taken, and the node with the highest probability after the final frame is processed is taken as the start of the most likely back trace to produce the most likely word sequence.
For W words and on average N states per word, then for each time frame, W × N internal token propagations and W external token propagations needs to be performed. Each interl propagation involves the calculation of the output probability and 2 or 3 add and compare steps per state.
Normally, the execution time for internal propagation is dominated by the state output probability calculations. For example, if we had in total K output distributions with M Gaussians and a vector of size V, then K × M × V × 2 multiply or adds per frame. For relatively low complexity systems (K = 2000, M = 10 and V = 39), then this results in approximately 1.5 million multiply add operations per 10 ms frame, as well as the performance hit of the earlier language and acoustic modelling techniques.
Pronunciation Organisation
Acoustic modelling has an impact on the construction of recognition networks, and thus on the search space. Monophones are simple acoustic models that allow the construction of word models from phone models.
One possible way of structuring monophone models is by simply putting connecting the different phone models for each word and then adding a start and end node to the word.
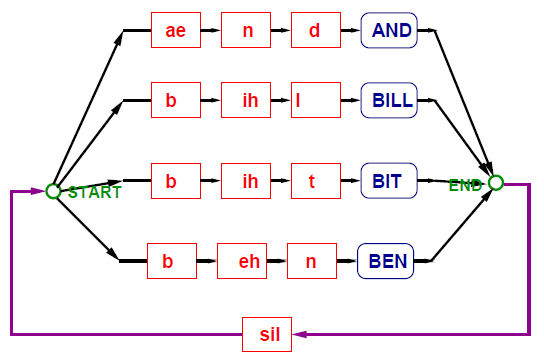
However, this parallel organisation is suboptimal. Many words start with the same phoneme, and consequently the same model at the start. Thus, some parallel branches can be merged into a tree-like structure.
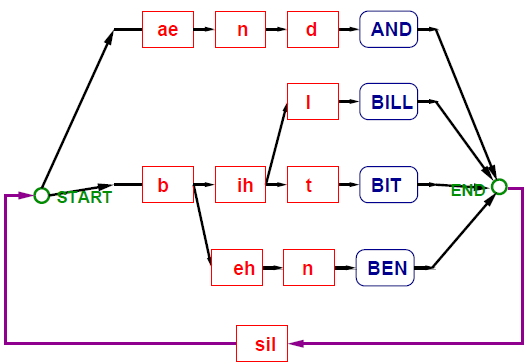
This reduction in the number of models in the network has a direct impact on the computational complexity. For the token passing algorithm, each state in the network has to hold exactly one token. Each token requires propagation and thus incurs computational cost, which can be lessened by reducing the number of models in this way.
Monophone models normally have inferior performance to triphone models. For word-internal models, these networks can be constructed similar to the monophone models, but the benefits of tree organisation for word-internal triphones are not as great.
For cross-word triphone models, which offer further benefits over word-internal triphone models, the construction of the network is more complex. Words will have multiple start and end nodes depending on the phonemes at the start of the next loop. This also has the issue of not having all word-end nodes connected to all word-start nodes.
To cope with this, the token passing algorithm must be modified so that the "best word" decision now has to be made for each set of links for entering one particular word.
Language Modelling
We must also consider the impact our language model has on our pronunciation organisation. For n-grams, the search space is vastly increased, as the language model probabilities can be interpreted as transition probabilities in a huge composite model between word starts and ends.
Alternate methods must be found to deal with this vastly increased search space. These use appropriate methods for constraining the search, but has the downside of not necessarily finding the best word sequence.
Beam Search
Beam search is a standard technique to limit the computational complexity while retaining reasonable performance.
The basic idea is to only compute likelihoods of those word sequences close (in likelihood) to the best path. Other paths are removed in a process known as pruning. This means that search errors are inevitably introduced due to suboptimal decisions.
For beam search, two steps have to be added to the search algorithm. The first is to compute the highest likelihood Lmax(t) of all tokens qt in the complete network at each time instance t. The second is the pruning process. This removes all tokens with a likelihood below Lmax(t) - Lthresh. Lthresh can be set to yield the desired speed/performance trade-off.
There are alternatives to Viterbi search also, but they are not discussed in depth here.
One such alternative is a fast match procedure. In these techniques, the search procedure is greatly enhanced by looking forward into the future (i.e., a few frames ahead) to make local decisions on pruning.
Another technique is stack decoders, which run time-asynchronously and allow seamless integration of high context depths for language and acoustic models - their main reason for popularity. However, pruning is difficult in this framework, and substantial search errors can occur. A* search is one example of a stack decoder.
Multi-pass search decodes the data multiple times with models of varying complexity. For example, monophone models could produce word networks of the words most probably associated with that utterance, and this word utterance is used as a constrained search space for use with higher complexity models, such as cross-word triphones or n-gram language models.
Adaptation
The output of a speech recognition system can be used to improve performance in the current acoustic and linguistic environment. Theoretically, all knowledge sources (vocabulary, acoustic and language models) can be adapted, however the most important technique is the adaptation to the variability of speech signals for different speakers - speaker adaptation. The other forms of adaptation include environment adaptation, accent adaptation, topic adaptation, etc.
The aim of speaker adaptation is to improve the quality of the speaker independent speech recognition output by use of speaker specific information in the recognition process. With speaker specific adaptation data, the components of the speech recogniser are changed to yield lower errors rates - the resultant system is called speaker adaptive (SA), as opposed to speaker independent (SI) or speaker dependent (SD).
An adaptation scheme is considered good if near speaker dependent (SD) performance can be achieved with sufficient data, and this adaptation can be achieved with small amount of data.
Two ways of adapting to a speaker includes adjusting the model parameters and modifying the features - the latter is called speaker normalisation.
Commonly there are considered two forms of speaker variations in speech signals: linguistic differences and physiological differences.
With linguistic differences, accents account for large variations between speakers. These effects can be handled in the lexicon as long as the change is consistent, and often, rules can be devised to predict these changes. In addition, there are idiosyncrasises associated with particular speakers. Another linguistic difference is that of speech rate (which is often dependent on accent), which is a difference that can not be handled by the lexicon.
Physiological differences include those such as gender, which has a profound impact on the whole structure of the speech signal - thses are called inter-speaker variability. Intra-speaker variability includes various transitory effects (such as having a cold) that alters the speech.
Speaker adaptation aims to rapidly adapt a recognition system to a particular speaker. A sample of speech from the new speaker is used to generate an adaptation mapping, and all further processing of the speaker uses this mapping. Some types of acoustic adaptation include: speaker classification, where an appropriate model set for a particular speaker is selected; feature normalisation, which uses mappings on the feature vector space to make all speakers appear similar; and model adaptation, which attempts to re-estimate the model parameters for a particular speaker.
Speaker adaptation may be performed in a variety of different modes. In supervied adaptation, the transcription of the adaptation data is already known, which contrasts to unsupervised, where the transcription is unknown, and must be estimated.
Static, or block, adaptation is where all of the adaptation data is presented before the final adapted system is produced. By contrast, dynamic, or incremental, is when an adapted system is produced after only part of the adaptation data has been presented. The adapted system may be further refined as more adaptation data is presented.
The particular mode of adaptation has consequences for the adaptation scheme in terms of computational load (is it necessary to update the models more than once) and the accuracy of the adaptation.
Speaker Clustering
In speaker clustering, a large number of model sets are generated, each one corresponding to a different speaker. The adaptation problem then reduces to deciding which model set the current speaker belongs to - a speaker identification problem.
In practice, it is not possible to generate a model set for every individual speaker, due to limitations of training data. Speakers are therefore clustered into similar speaker groups, and model sets are trained for these speaker groups.
During adaptation, the most suitable speaker group is selected. Hence, the speaker adaptation problem is separated into a clustering task and a classification problem.
In practice, this approach is problematic. The spectral variation of speakers, even within a cluster, may be large. Additionally, new speakers may not be well represented by the training set of speakers, and it is assumed that the differences between speakers are uniform across a model set.
Improved techniques such as eigenvoices or cluser adaptive models exist.
Feature Normalisation
In feature normalisation, parameters in the extracted features are adjusted to optimal values for a certain speaker. The aim is to lower or even remove the inter-speaker variability of speech signals.
With this approach, normally high efficiency is reached, but due to the small number of parameters, results rarely reach SD performance.
The most well known techniques for feature normalisation are vocal-tract length normalisation, where the length of the vocal tract is estimated, and the spectral shifts calculated accordingly, and linear cepstral transformation, where a general linear transformation of the cepstral features is used.
Algorithmically, both schemes are related - vocal-tract length normalisation can be approximated by linear transforms.
Vocal-Tract Length Normalisation
Vocal-tract length normalisation (VTLN) is a simple normalisation scheme that acts on the frequency axis.
Several schemes for estimating the warping factor include discrete search, where a set of discrete warping factors are examined, typically in the range of 0.88 to 1.12. The on yielding the maximum likelihood is selected.
An alternate scheme is direct measurement, where the VTLN factor is found by, for example, directly measuring formant frequencies.
Once the warping factor has been estimated, the mapping can be applied to data by: time-domain resampling, where the time-domain waveform is resampled using the new warping factor - this also changes the pitch and rate of speech; filter-bank shifting, where the centre frequency of the filterbanks is altered according to the warping factor; or cepstral transformation, which achieves similar effects as above by directly manipulating the cepstra by, e.g., multiplying an MFCC by a 39×39 matrix of rank 1.
Model-Based Adaptation
Model-based adaptation approaches have become increasingly popular. The aim is now to alter the parameters of, for example, a speaker independent model set to be more representative of a particular speaker.
Two approaches are common here: maximum a-posteriori (MAP) approaches, which have been used extensively for speaker adaptation, and smoothing; and linear regression, where a linear transformation is applied to the Gaussian mean (and possibly variance) parameters.
One problem that occurs with these model adaptation approaches is that of unobserved Gaussians - i.e., when there are no frames of adaptation data that correspond to a particular part of the model. This is a more general problem with speaker adaptation, as wehen dealing with small amounts of adaptation data, few Gaussians will be observed in the adaptation data.
MAP Estimation
In maximum likelihood training, the set of model parameters M are found by maxmising the likelihood p(O|M) of the training data O. MAP estimation attempts to find the model parameters by optimision p(M|O) (using Bayes rule). MAP aims to move towards a specific speaker-dependent model.
The influence of the prior (the speaker independent distribution), p(M), may be explicitly seen. When a non-informative prior is used, the MAP estimate becomes the ML estimate. MAP estimation techniques have been used to adapt the means, variances and mixture weights for CDHMM systems. We only cover mean adaptation here - μ is the most important parameter, as an incorrect δ does not change p as much as an incorrect &mu does..
MAP estimation will, given sufficient adaptation data, yield the same performance as a speaker-dependent system. The MAP estimate of the mean of state j is given by:
μMAP = (δj2μpj + δpj2 ∑Tt=1 Lj(t)o(t)) / (δj2 + δpj2 ∑Tt=1 Lj(t)), where δj2 is the assumed known variance, μpj and δpj2 are the prior mean and and variances, and Li(t) = P(q(t) = i | O) is the state level posterior probability.
We therefore need to determine the prior mean and variance, μpj and δpj2. When used for smoothing these were simply, for example, the context independent model parameters. In speaker adaptation, they may be estimated from S speaker dependent (or multi-speaker) models: μpj = ∑Ss=1 csμj(s); δpj2 = ∑ cs(μj(s) - μpj)2 - where ck is the weight assigned to the kth cluster data.
Alternatively, a parameter, τ, can be used to change the weighting between the prior and specific models in classification. This ratio is τ = &deltaj2/δpj2, and is typically in the range 0-100.
Once this value has been set, we can then determine μ^ = (τμprior + ∑t Lj(t)o(t)) / (τ + ∑ Lj(t))
These techniques basically minimise the different between what has been observed, and the transforms.
This only allows observed Gaussians to be updated. However, it is known that high correlations exist between the various states of the model sets, and various modifications to MAP have been suggested to handle this.
Least Squares Linear Regression
A second class of model adaptation is based on a linear transform of the model parameters, thus μ^j(s) = A(s)μj + b(s), where A(s) is an n×n matrix and b(s) is a vector of length n.
These describe the transform from the SI model to the particular speaker and can alternatively be represented as μ^j(s) = W(s)ξj, where ξ = [ 1 μj1 ... μjn ] T, where W(s) is an n×(n+1) matrix, and ξj is the extended mean vector.
Again, we have the problem of unobserved Gaussians, and also the problem of limited training data for each transformation. It is therefore necessary to tie the transformations over a set of Gaussians.
Initially, we could consider a single transform for all Gaussians. One simple estimation scheme for W is least squares. This has a simple solution that W(s) = (∑Mj=1∑Tt=1 Lj(t)o(t)ξjT) × (∑Mj=1∑Tt=1 Lj(t)ξjξjT).
Maximum Likelihood Linear Regression
The transformation matrix W(s) may also be estimated such that the likelihood of the adaptation is maximised - Maximum Likelihood Linear Regression (MLLR). When Σj = I for all states, then this is the same as Least Squares Linear Regression (LSLR).
The Expectation-Maximisation algorithm can be used for this purpose. MLLR have been found to outperform LSLR, and naturally fits into iterative EM schemes. Rather than using a single transform, multiple transforms may be used, using so-called regression class trees.
A matrix multiplication is essentially a rotation and scaling operation. Hence, for all classes associated with a single transform (for example, all triphones with a certain centre phone), then we assume that if the two classes are "close" in acoustic space for speaker A, then they will also be "close" in acoustic space for speaker B.
The threshold used in the regression class tree will be a function of the number of parameters in the linear transformation. For simple offset transformation matrices, the transformation is μj(s) = μj + b(s), and the number of parameters is n.
For diagonal transformation matrices, only the leading diagonal of the matrix and the bias are non-zero. Here, all elements are independent of one another: μji(s) = aii(s)μji + bi(s). This leaves us with 2n parameters.
In full transformation matrices, all elements of the matrix may be non-zero, resulting in n(n + 1) parameters. Block diagonal matrices are where the matrix is partitioned into rectangular smaller matrices called blocks, where these blocks go across the diagonal of the matrix. In this approach, the number of parameters is (n/b)2 + n, where b is the number of blocks.
Block diagonal and full transformation matrices have been shown to have the best performance.
Other adaptation schemes include language model adaptation. This is considered difficult due to considerable data sparsity effects - e.g., only a few trigrams would be observed in the adaptation data. Hence, adapting the language model using this adaptation data on a model with many millions of parameters may be minor.
A simple language model adaptation scheme is the use of unigram cachces. Here, a fixed size window over recently recognised words is used to obtain a word unigram distribution. This is then combined with the standard (possibly trigram) language model. However, despite the fact that perplexity can be reduced considerably, the impact on WER remains low.
Another adaptation method is lexicon adaptation. Schemes for lexicon adaptation are rarely used due to data sparsity effects. In theory, the dictionary can be modified to allow for speaker specific accents, however in practice, the acoustic models and dictionary both encode this type of information, and it is often more effective to use standard acoustic model adaptation such as MLLR.
Spoken Dialogue Systems
Automatic speech recognition enables the construction of spoken dialogue systems (SDS). Dialogue takes place between a computer and a human, and usually enables access to databases - in many cases over telephone lines.
Such a system has requirements including accurate recognition, being mixed initiative, confidence measures, natural output messages, minimal latencies, unconstrained user sentences, or low computational cost and development time.
The architecture of an SDS can be considered as a loop, starting and ending with the user, consisting of the following components:
- A recogniser, typically an ASR system;
- An understander, which performs parsing and semantic analysis of the input;
- A dialogue controller, which is typically implemented as a state machine that switches between dialogue states;
- A database, which usually has some simple (like SQL) interface;
- A message generator, which does automatic generation of appropriate answers or questions (in a textual form);
- A speech synthesiser or feedback generator (which can include waveform generation).
With small vocabularies, the systems tend to be menu driven and can be quite tedious (compared to touch tone dialing, but with voice) - but simple to use. However, the high interaction time does not allow for complex data access.
Medium vocabularies allow for more complex and effective systems in terms of dialogue if the user knows what to say, but it is difficult to express which words are in the lexicon. Large vocabulary systems with a realistic vocabulary will allow virtually natural dialogue as the user can say anything - but is problematic to implement, particularly in the understanding stages.
The basic architecture of most currently deployed commercial systems is based on the use of context free grammars. The grammar the recogniser/understander has is switched depending on which state the dialogue controller is in.
This generic framework allows a very wide range of tasks, and is preferred because the integration into search in recognition is simple. These systems tend to be highly scalable with respect to complexity in state control and grammar, and tend to have many additional features, such as speech detection, filler models (handling out-of-vocabulary words), the ability to "barge-in" and can provide confidence scores.
Recognition grammars can be expressed in terms of "slots" and their surroundings. A grammar can be translated into a word network (similar to a lattice), together with the appropriate tags. The word network can be then searched directly in Viterbi search using token passing to determine which value the "slots" in the grammar were filled with, and which rule was used.
Using a simple energy detector can be used to detect silence. However, this does not work well, as some speech signals have very low energy (e.g., fricatives), and it is sensitive to non-speech background noise, or echo from the speech synthesis. More sophisticated schemes for silence (or speech activity) detection exist, which often use GMMs.
One effective method for silence detection is the recogniser itself. One option is to buffer 1-2 seconds of speech, and to run the energy detector with a low threshold (many false positives - where speech is presumed to occur, but virtually no misses), and if the SAD is activated, the recognition (where the recogniser includes silence models) runs over the buffer, and if no speech was recognised, the recogniser is reset. This can also be used to give feedback - e.g., "speak louder please".
Dialogue design has to take into account that recognition can introduce errors. One strategy is to confirm decisions made as the dialogue progresses, however for better dialogue flow, it is important that the user can interrupt the speech output of the system (mixed initiative systems).
For this purpose, the recogniser has to be active when speech output is generated. In normal situations, the speech output and input channels are not decoupled, which means that the recogniser will try to recognise the output speech. A standard approach here is to use echo cancellation. We can assume that the recorded signal is a linear function of the synthesised function. The effect can then be removed by subtracting the filtered signal from the original signal. The filter parameters are adjusted every few 100ms to allow for optimal performance - an adaptive filter.
Prompt generation of feedback forms an essential part of SDS. Depending on the system complexity, speech output can be generated by replaying pre-recorded messages, automatic sentence generation by fragment concatenation, or text-to-speech synthesis. Text-to-speech synthesis is the most commonly used form of speech synthesis in state-of-the-art dialogue systems. An intermediate interface text is used between message generated and synthesis.
The generation of text on the basis of dialogue state can be performed using simple parameterised templates, or linguistic generation from grammars. In the latter case, an input of semantic units is given, and the grammars hold the relevant syntactic information.
One spoken dialogue system is that of the "voice web". For the voice web, a user uses a voice browser to "surf the voice web" based on the dialogue state of the user, and then downloads a document for the user which contains information (to be read out) and further state information.
One standard for "surfing the voice web" is the VoiceXML standard, from the W3C.
A VoiceXML document is capable of handling typical grammar based dialogues in a platform and browser-independent way. VoiceXML supports grammars as specified by the Speech Recognition Grammar Specification, which are typically cached and re-used. DTMF tone handling is also allowed in the specification, as is handling for events (such as disconnects, no input, URL errors, etc), synthesis for text prompts which can be annotated to improve the overall quality, and for executable content, based on JavaScript/ECMAScript.
Speech Synthesis
Speech output from systems is now commonplace, however, the form of input to the synthesiser and the methods used for generating speech vary considerably.
One system is simply playback of whole pre-recorded messages, or concatenation of pre-recorded voice fragments. Other methods involve generation by rule of control parameters for a speech production model, or concatenation of pre-stored basic speech sounds.
The range of input and quality varies according to the scheme. When using pre-recoded material, the vocabulary of the system is limited, but the output is typically high quality. The latter 2 methods allow for arbitrary message generation, but the quality is harder to maintain.
Text-to-Speech (TTS) synthesis systems allow for arbitrary input, and the final two methods described above fall under the realm of TTS.
TTS is a two stage process. In the first stage, linguistic analysis is performed, which maps the input text into a standard form, determines the structure of the input, and finally how to pronounce it. The second stage deals with synthesis - the symbolic represenation of what to say is converted into an actual speech waveform.
Additionally, the linguistic analysis component can be used in determining pronunciations for speech recognition systems, particularly names, since they are not included in standard pronouncing dictionaries.
TTS systems are used in a wide range of application areas, include proof-reading in word-processors, language tutoring systems, information access over a telephone, as an aid to the handicapped, for implementing interactive systems, and in translation systems.
Linguistic Analysis
For linguistic analysis, the input is human readable text (potentially with special characters and abbreviations), and the output is a high level description of the speech sounds to be generated.
The initial stages of the process are designed to diambiguate the sense of each word or character, and the following stages deal with the translation of words, together with additional syntactically/semantically derived information, into a compact description of the sounds to be generated.
The stages in linguistic analysis are: text normalisation, morphological analysis, syntactic analysis, pronunciation generation, intonation, and phonological analysis.
Text Normalisation
Initially, the text needs to be segmented into semantically consistent chunks, e.g., paragraph breaks, topic changes, sentence boundaries or word boundaries. The standard (for English) is to use whitespace to indicate word boundaries, capitalisation and full stops to indicate sentence boundaries, paragraphs are defined by new lines, and titles and section can indiciate topic boundaries.
Text normalisation involves converting the unrestricted input into a standard form. The text processing stage appears at first sight to be trivial, but in practice it is very hard to make it robust to arbitrary inputs.
Issues in text processing include that of end of sentence markers, which are clearly important for synthesis. However, many systems also use end of sentence markers (such as full stops) to indicate, for example, an abbreviation. Abbreviation expansion is also an issue, especially as are ambiguous unless context is considered (e.g., 'St.' for 'saint' and 'street').
Other issues include that of numbers - pronunciation of a string of numbers depends on context (time, date, telephone number, etc), and of specialist terminology, such as expansion of chemical symbols.
Morphological Analysis
See COM6791 for more
on morphological analysis.
Performing morphological analysis can be useful for the generation of pronunciations. As most pronunciations are generated by looking up each word in a dictionary, then storing copies of all morphological variants of a lexeme can be prohibitive, which stemming can help. Additionally, morphological analysis can inform syntactic parsing (e.g., identifying affixes which give properties such as number, case, gender, etc).
Syntactic Analysis
Syntactic analysis is also useful to disambiguate words (some words are pronounced differently depending on their POS tag).
Pronunciation Generation
The pronunciation component is responsible for converting words into phone symbols. This issue is difficult due to the size of the vocabulary, and pronunciation for words varies between word senses, and some sort of word sense disambiguation (partially informed by earlier morphological and syntactic analyses, as well as semantic analysis) is needed.
Additionally, continuous speech pronunciation is affected by cross-word phonetic context, but this is handled later on by phonological analysis.
To solve the issue of a vast word space, a limited vocabulary is used for lookup of the word's pronunciation, followed by morphological analysis if the word is not immediately in the dictionary. Finally, rules mapping letter to sounds can be used - this is essentially for unknown words, but can be highly complex.
Each stage is less accuarate than the preceeding, but the trade-off between that and the difficulty of creating a large dictionary which covers all possible words is necessary.
Intonation
The intonation component is responsible for making the speech sound natural.
Pitch, stress (intensity) and rhythm (timing) are all the prosodic elements of speech which are controlled by this component. These elements are not described by a sequence of phonemes, but prosody is still an important element in express semantic differences, but the exact types of differences are language dependent.
In Chinese (which is called a 'tonal' language) the same phone sequence can be expressed with up to four different tones per syllable. The identity of English words, by contrast, is not affected by prosody, but prosody does indicate sentence structure, the emphasis of certain words or sentence parts, and the mood of the speaker.
Prosody is mostly controlled by physical quantities, such as the duration of sub-phones, phones, syllables and whole words. These attributes can be stored on a unit basis, and affect rhythm and stress.
Additionally, the fundamental frequency contour F0 (the lowest frequency of the periodic waveform) is highly important. We also consider the local energy contour. This is important, but scaling proportionally to the fundamental frequency contour is commonly sufficient. Local raw energy is defined as a summation over a window of squared signal values.
Stress is primarily taken from a dictionary. Some systems allow additional stress to be applied to mark focus. Current systems have limited capability for generating natural intonation, and usually a very neutral ("boring") tone is adopted.
The rhythm of speech is defined by its temporal structure, which can have many influencing actors. Variation can be described on roughly a phone level, e.g., steady sounds (e.g., vowels) vs. transient sounds (e.g., stop consonants), the position in the world of a phone, and for lengthening of stressed syllables.
Pitch is a perceptual quality, and is closely related to the fundamental frequency F0.
Intensity defines the stress pattern, and is mainly determined by phone identity and sequence, and hence is often taken from the dictionary (lexical stress). It is less influential than pitch or rhythm.
In English, we can see that pitch falls gradually to the end, with local variations influenced by the phrase structure of the sentence and the sentence stress pattern. The last syllable that carrys the primary stress in any breath group shows the biggest pitch change - a pitch fall indicates the sentence is a statement, whereas a pitch rise indicates that the sentence is a yes/no question.
To model the F0 contour, we first need a description of an intonation contour, and a conversion to a sequence of values. In the superposition model, descriptions of phrase and accent are filtered and superimposed on a baseline value.
Phonological Analysis
Phonological analysis is the final symbolic processing stage. The primary function of this stage is to map phones into context specific versions called allophones.
Waveform Generation
The synthesis stage of a TTS system must convert the allophone symbol sequence into a continuous speech waveform, and apply the correct innotation.
Common forms of synthesis include formant-based, articulatory and concatenative. Formant-based synthesisers can be either parallel or serial, and vocal tract filter is formed by combining a number of resonances. Articulatory synthesis attempts to model the speech production system, and models of the articulators and vocal cords are used - the original "speech machine". Concatenative synthesis explicitly uses synthesis units - representative examples of each unit is stored and used for synthesis.
Many of these systems make use of the source-filter model of speech production. The source-filter model represents the vocal tract in the form of a time-varying filter, and assumes a binary selection between two forms of excitation sources: a noise and a pulse generator. Excitation is modelled as either a train of impulses, or by noise. The vocal tract filter has to be modified frequently (e.g., every 10 ms)
The excitation is described by F0 and energy alone, but the parameters of the filter can take many forms, such as descriptive using formants, or signal representative using spectral representations.
Formant Synthesis
In formant-based synthesis, the symbol sequence is converted into a sequence of parameter vectors. Each parameter vector describes the spectral envelope in terms of the formants, and the signal can be generated by sending the excitation signal into a bank of resonators. Parallel formant synthesisers are preferred to serial synthesisers, because they allow the formant amplitudes to be individually controlled.
These resonators can be implemented in the form of so called 2-pole resonators. These are simple signal processing elements with only two parameters to control the width and extent of a resonance.
A typical formant parameter vector consists of F0, the fundamental frequency, AV, the level of voicing, A1-A4 and F1-F3 for amplitude and frequency of the first 4 formants respectively, except F4 which is fixed, and AN and FN, which can be used for a very broad low frequency resonance which can be added to boost low frequencies (e.g., for nasals). Adjacent formants are added in anti-phase in order to compensate for the 180° phase shift which occurs in the resonating channel.
These parameters are updated every 10ms, however in order to produce natural sounding speech, a smooth transition is required between the parameters. The evolution of each parameter over time is computed from a set of tables, one for each allophone. Each table contains a target parameter set for the formant frequencies, and transition information from the current allophone to the next to be computed.
These parameters include FC, a fixed contribution from the current allophone, Tgt, which is the target value of the following phone, ID, the number of transition frames within the current allophone, and ED, the number of transition frames in the following allophone.
The transition is linear from the targets to the boundary value fb which is calculated by fb = FC + Tgt/2.
Formant-based synthesis is computationally very efficient, with low cost implementations possible. The naturalness of the output is limited, but it has been widely integrated into TTS systems.
There are a large number of coupled parameters to tune in formant synthesis. Formant frequencies and bandwidths are inherently difficult to estimate from speech data.
Articulatory Synthesis
The approach here is that vocal tract filler parameters are automatically generated from modelling articulator (i.e., tongue, jaw, palate lips - the fundamental articulators) movement.
It can be thought to as similar to formant synthesis. Parameters are heuristics estimated on a per-phone basis in the form of a description of the vocal tract. Additionally, transition models are used to describe the transition of articulators from one state to another.
However, it is difficult to get the exact articulator position from humans (X-ray is one method, which makes gathering huge amounts of data very difficult), and some sort of three dimensional representation would be required. Additionally, once the data has been collected, interpretation is difficult (how exactly do you represent an articulator state?).
Concatenative Synthesis
In many applications, memory does not play an important role, and quality of speech is of greater importance. High quality can be achieved by storing sound fragments (which is memory intensive) which are then joined together to form a complete sentence - concatenative synthesis.
There are three issues which must be considered for concatenative synthesis. The first is that of the synthesis units.
The choice of synthesis units is important. There is a trade-off between longer and shorter units, and multiple examples of the same synthesis units may be stored and selected, according to duration and pitch contour.
Long units have few concatenation points, and also typically smaller concatentation discontinuities, resulting in a longer time-scale "naturalness". However, if short units are used, fewer are required. The choice of synthesis units is therefore a balance of number against length.
The type of units considered are similar to those considered for speech recognition. One popular unit is the diphone, which is a segment starting at the centre of one phone, and ending in the centre of the next. Diphones are desirable as they preserve transitions between points (which are difficult to synthesise), and have concatentation points in the middle of phones, which is spectrally the most stable point. This minimises concatenation discontinuities. Additionally, diphones can be simply derived from real speech, resulting in a mroe natural output.
Additionally, we must also consider how these units are represented. Common formats include linear prediction coefficients and waveforms. The final issue to be considered is that of concatenation - how can we connect the speech segments together without noticeable connection points resulting in a loss of quality?
A wide range of concatenative synthesis schemes have been proposed. One common scheme for waveform concatenation is Pitch Synchronous Overlap and Add (PSOLA). This is pitch synchronous, which means for each sample waveform, we have to store the "pitch location" (i.e., the places of glottal closure), and the spacing is subsequently defined by the fundamental frequency. Concatentation then occurs through overlap and add, which changes the pitch or duration of a sound.
The simplest (and oldest) form of concatenation is time-domain (TD) PSOLA. This requires large amounts of memory to store a waveform, and does not allow spectral smoothing at concatenation points, so the choice of synthesis unit is very important. Additionally, it does not rely on the source-filter model approximation.
The basic procedure is to break up the natural speech signal by applying Hanning windows pitch synchronously in voiced regions, and evenly spaced in unvoiced regions. The pitch is then raised or lowered and the duration altered for the required intonation, and the sequences added together, compensating for the number and amplitude contributing to the synthetic signal.
The above procedures can also be used for time or pitch modification of waveforms. PSOLA requires a carefully labelled database of speech sounds, but allows for the generation of very naturally sounding speech. However, it is not flexible in changing speaker characteristics, but the quality can be improved by having multiple examples of each unit (e.g., the diphone).