Problems and Solutions
A problem is a description of the:
- assumptions on the inputs
- requirements on the outputs
A solution is a description of an algorithm and associated data structures that solve that problem, independant of language.
e.g., given a non-negative integer n, calculate output: ![]() . You could solve this:
. You could solve this:
- s ← 0
for i ← 1 to n
do s ← s + i; - s ← n × (n + 1)/2
- if ∃ p . n = 2p
then s ← n/2
s ← s × (n + 1)
else s ← (n + 1)/2
s ← x × n
Are these correct? If we assume they are, how do we compare them to find the best one?
Correctness
You can be formal about correctness using predicates and set theory, but in ADS, we shall be semi-formal and informal.
An invariant is a property of a data structure that is true at every stable point (e.g., immediately before and after the body of a loop (for loop invariant), the procedues and functions of an ADT (for data invariant)).
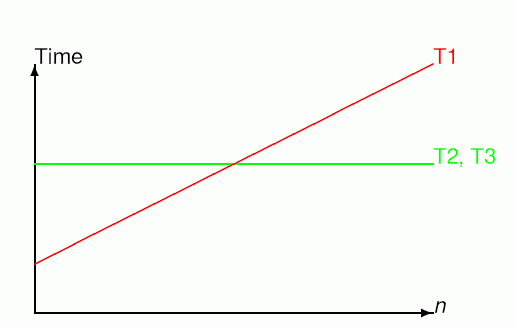
The first suggested solution has invariant ![]() and terminates when i = n. The other two algorithms are correct by the laws of arithmetic. Although all 3 algorithms are correct, none can be correctly implemented due to finite limitations. The way to find out which algorithm is better than others is by measuring resource usage. For our solution: T1 = λn · (2i + a + t)n + (2a + t) and T2 = T3 = λn · m + i + d. i is the time to increment by 1, a is the time to assign a value, t is the time to perform the loop test, m is the time to multiply two numbers and d is the time to divide by 2.
and terminates when i = n. The other two algorithms are correct by the laws of arithmetic. Although all 3 algorithms are correct, none can be correctly implemented due to finite limitations. The way to find out which algorithm is better than others is by measuring resource usage. For our solution: T1 = λn · (2i + a + t)n + (2a + t) and T2 = T3 = λn · m + i + d. i is the time to increment by 1, a is the time to assign a value, t is the time to perform the loop test, m is the time to multiply two numbers and d is the time to divide by 2.
Therefore, we can see that the time resource usage for the second and third algorithms is constant and for the first algorithm it is linear. If we plotted a graph of T1 against T2 (and T3) we see that for a finite value of n then T1 has less usage, but for an infinite value of n T1 has greater usage. From this, we can assume that either T2 or T3 are the better algorithms.
Asymptotic Complexity
∃n0, c . n0 ∈ N ^ c ∈ R+ ^ ∀n . n0 ≤ n ⇒ fn ≤ c.(gn)
This can also be written as f = Ο(g). However, this means there is an ordering between f and g (not an equality).
f = Ο(g) means that f grows no faster than g. From this, we can create the related definitions:
- f = Ω(g) - f grows no slower than g. g = Ο(f)
- f = Θ(g) - f grows at the same rate as g. f = Ο(g) ^ f = Ω(g)
- f = ο(g) - f grows slower than g. f = Ο(g) ^ f ≠ Θ(g).
- f = ω(g) - f grows faster than g. f = Ω(g) ^ f ≠ Θ(g).
For asymptotic complexity, given functions f, g and h, we can say they have the properties of being reflexive and transitive, therefore the relation _ = Ο(_) is a preorder.
Another property we can consider is symmetry.
λn · 1 = Ο(λn · 2) (take n0 = 0 and c = 1). Also, λn · 2 = Ο(λn · 1) (take n0 = 0 and c = 2). This proves that Ο(_) is not antisymmetric.
To shorten down these expressions, it is traditional to drop the λn, so λn · 1 becomes just 1.
We can also combine functions, so:
- f = Ο(g) => g + f = Θ(g)
This allows us to drop low-order terms, e.g., 7n = Ο(3n2) => 3n2 + 7n = Θ(3n2) - f = Ο(g) ^ h = Ο(k) => f × h = Ο(g × k)
This allows us to drop constants, e.g., 3 = Θ(1), so 3n2 = Θ(1n2)
We can also combine these laws to get such things as 3n2 + 7n = Θ(n2).
There are also two special laws for dealing with logarithms:
- 1 = n0 = ο(log n)
- ∀r, r ∈ R+ ⇒ log n = ο(nr)
From these rules, we derive most of what we need to know about _ = Ο(_) and its relatives.
In general, we can simplify a polynomial to be an ordering between the polynomial and it's largest term, also, we can treat log n as lying between n0 and nr for every positive r.
Classifying functions
We can class functions according to their complexity into various classes:
| Name | fn=t | f(kn) |
| Constant | 1 | t |
| Logarithmic | log n | t + log k |
| Linear | n | kt |
| Log-linear | n log n | k(t + (log k)n) |
| Quadratic | n2 | k2t |
| Cubic | n3 | k3t |
| Polynomial | np | kpt |
| Exponential | bn | tk |
| Incomputable | ∞ | ∞ |
The f(kn) column shows how multiplying the input size by k affects the amount of resource, t, used.
Complexities of Problems and Solutions
For our example problem 1, how many times is fp = x executed with input size of n = (z - a) + 1? In the best case, this is 1 (x is found immediately), however in the worst case, this is n. Thus we can say that the complexity class is linear.
The average case time depends on assumptions about probability distribution of inputs. In practice, the worst case is more useful.
Abstract and Concrete Data Structures
Many of the problems of interest are to implement abstract mathematical structures, such as sequences, bags, sets, relations (including orders), functions, dictionaries, trees and graphs, because these are of use in the real world.
Common operations include searching, insertion into, deletion from and modification of the structures.
However, our machines are concrete, so our implementations of these abstract structures must be in terms of the concrete structures our machines provide.
We normally consider an abstract data structure as a collection of functions, constants and so on which are designed to manipulate this. We came across this in Principles of Programming as Abstract Data Types. Our aim here is to make the more common functions efficient, at the expense of the uncommon functions.
The relationship between an abstraction and concretion is captured by an abstraction invariant (or abstraction relation). e.g.,:
- A set of elements s is represented by a list l with the property: s = { l(i) | i is an index of l }
- A set of elements s is represented by an ordered list l with the property: s = { l(i) | i is an index of l }
- A set s is represented by a sequence of lists q with the property: s = { (concat(q))(i) | i is an index of concat(q) }
Contiguous Array
This is an concrete data structure, where each item in an array directly follows another. The advantage of this method is that the component address can be calculated in constant time, but it is inflexible (you need to find a whole block of spare storage that can hold all you want to store in one long row)
Pointer (Access) Structures
This is also a concrete data structure. We already covered pointers in PoP. To lookup the pth item in a pointer structure requires p lookups, so this example is linear in p. Extra space is also used for pointers, however, it is flexible (can easily fit in spare space, things can be added to and from it easily using new pointers, etc...
Linear Implementations of Dictionaries
An entry in a dictionary consists of two parts: a key, by which we can address the entry and the datum, attached to the key.
For entry e we can write key(e) and datum(e), and also e = make_entry(key(e), datum(e)). We can say that a dictionary, d, is a set of entries, where if e0 ∈ d ^ e1 satisfy key(e0) = key(e1), then datum(e0) = datum(e1). This is a finite partial function.
We can say that the main ADT operations are:
- is_present(d, k)
- lookup(d, k)
- enter(d, e)
- delete(d, k)
Other operations could include modify(d, k, v) and size(d).
Problem
Choose a concrete data structure to support the abstract concept, and algorithmns to support operations over this structure, such that a good balance of efficiency is acheived. It may be that we need to sacrifice the efficiency of less common operations to make the more common ones more efficient.
These solutions are simplistic, and there are better way to accomplish this
An Array
This is a machine-level structure with a fixed number of cells, all of the same type. Each cell can store one value and is identified by an address. The time taken to access a cell is independent of the address of the cell, the size of the array and the content of the array.
Models
- A pair of: an array, e of length max and a number, s, in the range s..max, which shows the current size of the array.
- A triple: as above, but with a boolean u that tells us whether or not a cell is active.
Is a value present?
In the pair model, a linear search in the range 0..s would be needed, whereas for the triple, a linear search from 0..max, checking u(i) is true.
For the pair model, the complexity is Θ(s) and for the triple, the complexity is Θ(max), and both are linear.
Value lookup
Again, this is a linear search in both cases and for the pair model, the complexity is Θ(s) and for the triple, the complexity is Θ(max).
Enter
In the pair model, you go through the list checking that no entry already exists with that key, then you add a new entry to the end (at s) and increase s. For the triple model, you do a value present check, and then enter the value into the first inactive cell (where u(i) is false).
For the pair, the complexity is Θ(s) and this is linear.
Deletion
There are two methods of implementing the deletion method. You could go through the array, moving data leftwards to over-write entries with key k, or you could go through the array, replacing key k with a special ghost value, and then compacting when there is no space left.
This is linear, however for the second strategy, you can then rewrite enter to use the first ghost it finds, causing optimisations.
Linked Lists
A linked list is a machine level structure with a variable number of cells, all of the same type. Each cell stores one value, and the address of the next value, so a cell is found by following pointers.The time to access a cell is linearly dependent on the position of the cell in the list, but independent of the length of the list or its contents. We already implemented linked lists in PoP.
Is a value present?
Using a temporary pointer, you can go through the list and compare the value at the temporary pointer to the value that you're looking for. This is linear in the length of the list.
Value lookup
This is essentially the same as the value present check, but returns the datum of that key, not just that it exists. Again, it is linear.
Enter
To enter data, you need to create a new cell, then set the pointer value to the pointer of the current list pointer. The list pointer is then updated to point at the new cell. This has a constant complexity.
Deletion
To delete something, you need to find the key to be deleted, and also the key that points to it. In the key that points to it, you need to update the pointer so that it now has the pointer of the cell to be deleted (i.e., it points to the next cell). The deleted cell is no longer part of the list and the garbage collector should come along and clean it up.
The raw material for an algorithm designer consists of assumptions on the input (stronger is better), requirements on the outputs (weaker is easier) and intelligence and imagination (more is better). We can improve the assumptions on our dictionary algorithms by asking that keys be orderable. We can then improve our algorithms to take advantage of this assumption.
Ordered Arrays
If you model the pairs so that for any array indeces i and j there is an ordering on i and j, you can use binary search, a logarithmic algorithm (an improvement over linear), for the is_present and lookup functions.
Enter
Use binary search to find the correct position, then for an existing key, you over-write the old value. For a new key, the array is slid one place right and the value is written into the hole. This is linear.
Deletion
This is the same as in an unordered array, but we can find the location in logarithmic time. The deletion process is still linear overall, though.
Ordered Linked List
is_present and lookup can't use binary search, as we can't find the middle of the list in constant time. We have to use linear search, but we can terminate earlier if we pass the point where it would be in the ordering, rather than going straight to the end.
Enter
This is like the non-ordered example, but the key must be inserted in the correct place in the list. Therefore, it is linear.
Deletion
This is as the unordered list, but you can now stop when the first occurance of a key is found. This is again linear, but the constants are lower.
Summary
s is the number of distinct keys in the dictionary. l is the length of the list.
| Complexity | is_present / lookup | enter | delete |
| Unordered array | s | s | s |
| Ordered array | log s | s | s |
| Unordered linked list | l | 1 | l |
| Ordered linked list | s | s | s |
For the ordered list, l = s. Additionally, leading constants change between the types, so where complexities appear the same, the leading constants could be much different. The exact value of the constants depends on the details of the implementation. Additionally, the array solution can waste space, as l must be allocated, and l > s.
Linear Priority Queues
Bags of items
Bags are sometimes called multisets. They are similar to sets. Sets have members, but bags have the same member more than once (multiplicity) - however order is not important so it is not a series.
 a,b,b
a,b,b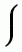 is a bag with 1 copy of a and 2 copies of b.
is a bag with 1 copy of a and 2 copies of b.- a,b,ais a bag with 2 copies of a and 1 copy of b.
- is an empty bag.
If we had the concept of the most important element in a bag, then we might have two operations: enter(b,i) and remove_most_important(b). We will also need is_empty(b), is_full(b), size(b), etc..., for completeness.
If the highest priority is youngest first, then this is a stack (LIFO) structure. enter and remove is normally called push and pop respectively. If the oldest is the highest priority, this is called a queue (FIFO) and enter and remove are normally called enqueue and dequeue respectively.
Both the stacks and queues abstractions can be implemented efficiently using arrays or linked lists. Regardless of whether it's implemented as a linked list or an array, the complexity will be constant.
To implement a queue as a linked list, we would need two pointers, f to the front and e to the back. The complexity for this is constant. To implement the queue with an array, you would need to have an index e of the next insertion point and the number (s) of items in the queue. To enter something into the queue, you overwrite the current value of e and then move e, and then to dequeue something, you would return e - s mod max, then decrease s. We use modulus arithmetic to allow the array to wrap round.
Following pointers may be slower than an array, so sometimes the array implementation is the better one.
Trees
Trees are an ADT that can be implemented using arrays or pointers, of which pointers are by far the most common. Trees can be used to implement other ADT's, such as collections (sets).
Structure
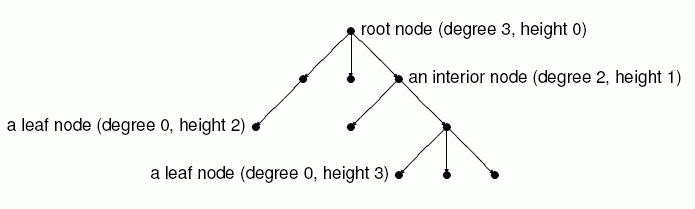
Nodes carry data and are connected by branches. In some schemes only leaf nodes or only interior nodes (including the root) carry data. Each node has a branching degree and a height (aka depth) from the root.
Operations on a tree include:
- Get data at root n
- Get subtree t from root n
- Insert new branch b and leaf l at root n.
- Get parent node (apart from when at root) - this is not always implemented.
These operations can be combined to get any data, or insert a new branch and leaf.
Binary Trees
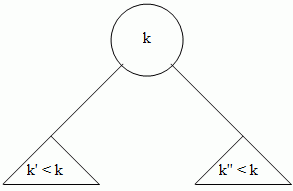
A binary tree is a tree with nodes of degree at most two, and no data in the leaves. The subtrees are called the left and right subtrees (rather than 'subtree 0' and 'subtree 1'). An ordered binary tree is one which is either an empty leaf, or stores a datum at the root and:
- all the data in the left subtree are smaller than the datum at the root,
- all the data in the right tree are larger than the datum at the root, and
- any subtree is itself an ordered binary tree.
Usual implementations use pointers to model branches, and records to model nodes. Null pointers can be used to represent nodes with no data. As mentioned earlier, array implementations can be used, but they are normally messy.
An ordered dictionary can be used to implement a binary tree. Such a tree would be structured like this:
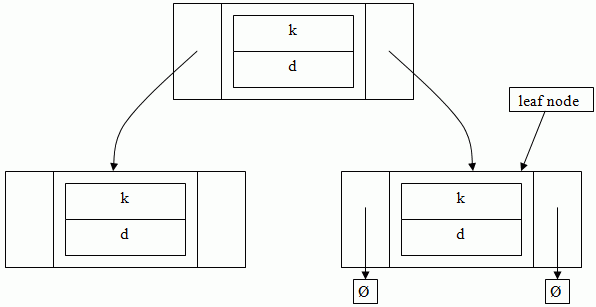
These trees combine advantages of an ordered array and a list. The complexity to traverse a complete tree is log2 n, however this is only if the tree is perfectly balanced. A completely unbalanced tree will have the properties of an ordered list and will therefore by linear.
When we are considering trees, we should now consider three data invariants:
- order
- binary
- balance
For more info on
red-black, see CLRS
or Wikipedia
There are two common balance conditions: Adelson-Velsky & Landis (AVL) trees, which allow sibling subtrees to differ in height by at most 1 and red/black trees, which allow paths for nodes to differ a little (branches are either red or black - black branches count 1, red branches count 0 and at most 50% can be red).
AVL Trees
In AVL trees, searching and inserts are the same as before, but in the case of inserts, if a tree is unbalanced afterwards, then the tree must be rebalanced.
Rebalancing
The slope is height(left) - height(right). For the tree to be balanced, slope ∈ {-1, 0, 1} for all nodes. If the tree is not balanced, it needs rebalancing using 'rotation'.
Wikipedia entry
on tree rotation
To rotate, you should set up a temporary pointer for each node and then re-assemble the tree by changing connecting pointers.
Deletion from a binary tree
There are different methods of deleting from binary trees. One is using ghosts. A cell could have a "dead" marker indicated (however, it must still have the contents for ordering purposes), but this is only useful if deletion does not happen often, otherwise the tree will end up very large with lots of dead cells. Insert could also be altered to use these dead cells (if they fit in with the orderings)
Another method that is used is propogation. Here, deletions are pushed down to a leaf, and pushed up cells must be checked to ensure they are still ordered. The tree may need rebalancing after this happens.
Lists will always be quicker than trees for deletion.
What about ternary trees? These would give us log3 n, which is < log2 n (where n > 1). In a binary tree: Θ(log2 n), but in a ternary tree, Θ(log3 n). However, log2 n = Θ(log3 n). The base is a constant, so can be disregarded for Θ purposes. However, ternary trees require harder tests for ordering, so any benefit from having fewer arcs are cancelled out. Tree rebalancing is much trickier, as rotation can not be used. In a case where pointers are very slow (such as on a disk), then ternary trees may be better.
B+-trees
These are sometimes called B-trees, which is technically incorrect. B+ trees are slightly different to binary trees in that the key and data are seperated. B+-trees are commonly used in disks.
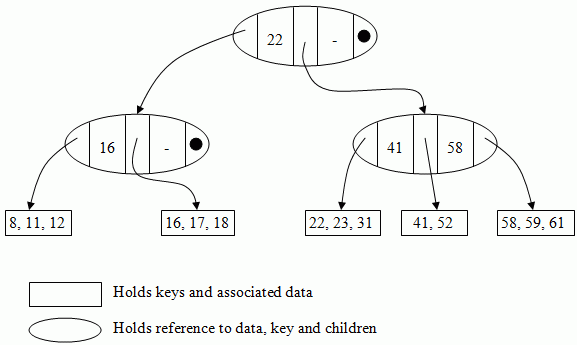
The invariants for a B+ tree are:
- all leaves are at the same depth (highly-balanced)
- root is a leaf or has 2..M children.
- non-root non-left nodes have ⌈m/2⌉..m descendantrs
- ordered
If m = 3 (as above), this is sometimes called a 2-3 tree. If m = 4, this is called a 2-3-4 tree.
Insertion
By adding 1, 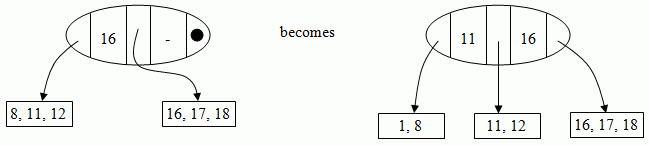
Nodes can also propogate up, if there isn't a spare child available.
Priority Queues
There is some ordering over the elements which tells us the importance of the item. One method of ordering is over time - as we saw earlier with linear priority queues.
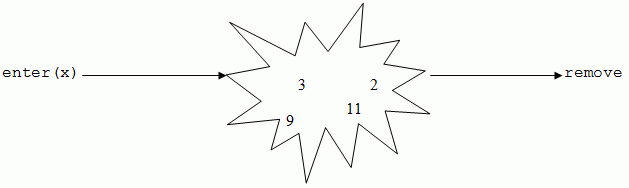
(Here, a low number means a high priority.)
The first invariant we should consider to implement this is to implement it as a binary tree. However, to make the invariant stronger, we should use heap ordering. This is where the highest priority is the root and each sub-tree is heap ordered. e.g., for our example above, a heap ordered binary tree would look like:
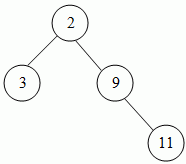
To enter a value, you need to pick any null entry and replace by the new value and then bubble up, e.g., put 1 as a leaf of 11. 1 is more important than 11, so swap the two values. 1 is then more important than 9, so swap again and continue until a point is found where 1 has nothing more important than it, which in this case is the root. This maintains the ordering and therefore restores the invariant.
To delete a value, pick any leaf, move upwards to the root and then bubble the value down, which is the opposite of bubbling up - however as there are two values to swap with, swapping always occurs with the most important of its children to maintain the ordering.
However, like trees we've looked at before, in the worst case, this can be linear in complexity, so we should strengthen our queue with a new invariant - balance. This balance invariant is stronger than the balance invariant we looked at in AVL and red-black trees, though. Here, we will only allow holes in the last row - this is perfect (or near-perfect) balance and gives us a logarithmic time complexity.
There is only one undetermined thing to consider - when there are multiple holes to insert into, which one do we use? By using another data invariant, we can reduce this nondeterminisism.
Left justification is where all the values in the last row are on the left.
From all of these invariants, the algorithm is now completely determined, so we now need to consider how to implement this tree.
If we used pointers, we'd need two down to the subtrees, and one up to the parent, in addition to a cell for data. However, as we know pointers are slow, this could be a slow implementation. Because we have very strong invariants, an array implementation is better, however the array will have a maximum stage, which is another invariant to consider.
Our implementation will therefore have an array h (1..m) and a number s which represents the size.
If h(k) represents some node, then we need to be able to find parent and children.
The parent can be found at h(⌊k/2⌋) and therefore we can find the left child at h(2k) and h(2k + 1). h(1) is the root.
As s is the size of the array, this makes h(s) the deletion point and h(s + 1) the insertion point.
This implementation is called a heap.
Merging Priority Queues
For efficient merging, we need to use a structure called a binomial queue. A binomial queue is a forest of heap-ordered binomial trees, with at most 1 tree of each height.
Binomial Trees
A single node is a tree of height 0 (B0), and a tree Bk + 1 is where two trees of Bk are attached together (one root is attached to the other).
Binomail trees are not binary - they can have many arcs.
To merge two queues together, we add two forests together (as in binary addition). However, as we can have at most 1 trees, some trees need to be "carried" (combined with the next tree up). This process is linear in the number of nodes.
Insertion
If you made x a single node queue, and then merge it with an existing queue you insert it into the queue - this is logarithmic.
Removing
To remove, you need to find the tree with the smallest root and remove it from the queue. You then remove the root from the removed tree which gives you a new set of trees of height Bk - 1, which can be merged back in with the existing queue. This is logarithmic.
Dictionaries as Hash Tables
There are two main implementations of dictionaries. One is with a simple keyspace (i.e., Index is 0..max-1, where max is a reasonable number). This can be implemented as an array, either as a pair of arrays or an array of pairs - where one is a value indicating whether or not the cell is active and the other is the contents.
The second implementation is a dictionary with an arbitary keyspace. Here, a hash function takes a key and gives us back an Index. e.g., if key = N, hash(k) = k mod max.
What if the key is a string? We treat A-Z as base-26 digits and then apply the hashing function to this. Horner's rule is an efficient hashing function.
(((k(#k - 1)) × 26 + k(#k - 1)) × 26 + ...) + k(1)
Horner's rule is linear, however if we use multiples of 32 instead of 26 we can bitshift, which is much faster. Another improvement we could make is that ensuring our values don't overflow by doing mod max after every multiplication. Making the max a prime value also increases efficiency.
A consideration is what happens if we try to put 2 pieces of data in the same cell - in a length 7 array, indexes 3 and 10 both point to the same place, so we get a collision. There are two hashing methods that work round this:
- Open hashing (sometimes called seperate chaining)
- Closed hashing (sometimes called open addressing)
Open Hashing
We have an array of small dictionaries, normally implemented using a linked list, so when a collision occurs, it is added to the dictionary.
To consider efficiency, we need to conside the loading factor (λ), which is the number of entries ÷ the number of cells. For open hashing, λ ≤ 1 (assuming a good hash function), making our average list length 1. Therefore, on average, all operations are Θ(1).
Closed Hashing
In closed hashing, a key points to a sequence of locations and there are several varients of closed hashing.
Linear Probe
hash(k) + i
When a collision occurs, find the next empty cell and insert it in there.
A collection of full cells is called a cluster, and searching for a key involves searching the whole cluster until you reach an empty cell. For this to be efficient λ ≤ 0.5.
If deletion occurs, the algorithm breaks, as an empty cell would break up the cluster and the search would stop early. A ghost must be used in this case.
Quadratic Probing
hash(k) + i2
This is essentially the same as linear, but the offset is i2. If the table size is prine, and λ < 0.5, insertion into the array is guaranteed, however without this condition, insertion can not be guaranteed.
Double Hashing
hash(k) + i.hash′(k)
The first hash computes the start and the second computes the offset from the start.
Of these hashing methods, open hashing is much more popular. With hashing, insert, delete and find are Θ(1) or close. Performing operations on all the entries on a dictionary in a hash table isn't so good, however. Creating a hash table also requires that you know the size.
If λ gets close to the limit for the algorithm so that it would either be unusable or not very efficient, you can rehash. Rehashing is create a new table (of approximately twice the size - the new table should be prime in size) and copy all the data across. This is very slow. Open hashing doesn't necessarily need rehashing, but speed does increase if you do it. You can also rehash tables down in size as well as up.
There are other dictionary implementations, such as PATRICIA, but we will not be covering them in this course.
Sorting
This brings us closer to our original definition of a problem. We have assumptions on inputs - that we have an array (or linked list) a with a given total order on the elements - and requirements on the outputs - namely that a is ordered (sometimes a different structure may be used in the output, e.g., a linked list when the original was an array) and bag(a0) = bag(a′).
We can use loop invariants to define our sorts. There are lots of different sorts, including:
- Bubble sort
- Shell's sort
- Quicksort
- Merge sort
- Insert sort
- Select sort
- Heap sort
- Bucket sort
- Index sort
Bubble sort should never be used.
Selection Sort
The first portion of the array is sorted and the second part isn't, but is known to be all larger than the front portion.
To sort, the smaller value should be selected from the back portion, and the first element of the back portion should be swapped with it.
The figure out the efficiency of this, you need to figure out the number of comparisons to be made. This will be (n-1) + (n-2)+ ... + i, which is Σn-1i=0 i, which is Θ(n2) always. In the worst case, Θ(n) swaps need to be made.
Insertion Sort
Like selection, but the back is not necessarily related to the front (it can be any size).
To sort, you take the first value of the back portion and insert it into the front portion in the correct place.
The efficiency of the comparisons in the worst case is 1 + 2 + 3 ... + n which gives us the Σn-1i=0 i formula again, which is Θ(n2) . However, in the worse case, comparisons are only Θ(n). The efficiency of the swaps at best is 0, but in the worst case this is Θ(n2), however this doesn't happen often (only if the list is reverse ordered).
We could have used binary search here, which would have theoretically improved the time to find the insertion point, but due to a high leading constant this makes it poor in practice.
This sorting algorithm is good for small lists - it has a small leading constant so the Θ(n2) isn't too bad. However, it is also good for nearly ordered lists, where the efficiency is likely to be nearly linear.
There are two theorems regarding sorting:
- Any sort that only compares and swaps neighbours is Ω(n2) in the worst case
- A general sorting problem has Ω(n log n) in the worst case.
Heap Sort
The heap has already been covered when we did priority queues.
- Every element is put in a heap priority queue (any implementation will do, but a heap is fast).
- Remove every element and place in successive positions in a, our sorted array.
n elements are inserted in log n time and n elements are removed in log n times, so n log n + n log n = Θ(n log n).
However, heap sort is not very memory efficient due to duplicating arrays. Also, it has a very high leading constant.
The Dutch National Flag Problem
This algorithm deals with sorting three sets of data. You have an array of data sorted into 4 partitions, 3 of known type and one of unknown. The partitions are ordered so the unknown type is the third one.
To sort, the first element in the unknown type is compared. If it's part of the first partition, the first element of the second partition is swapped with it, moving the second partition along one and growing the first partition. If it's part of the second partition, it's left where it is and the pointer moves on. If it's part of the last partition, it's swapped with the last member of the unknown partition, hence shrinking the unknown partition and growing the final known partition by one.
Quicksort
Quicksort was invented by Sir Charles Antony Richard Hoare and it consists of series of sorted areas and unsorted areas, where the unsorted areas are of a known size laying between the two sorted areas.
The starting and finishing states are special instances of the above invarient. The starting state is where the unsorted area is of size n and the sorted area is of size 0, whereas the finished state is where the unsorted area is of size n and the sorted area is of size 0.
The first step sorts to where there are three areas, of which the middle one is called the pivot. Everything before the pivot is known to smaller than the pivot, and everything after the pivot is known to be larger than the pivot - this is accomplished using the Dutch National Flag algorithm. Each unsorted section is then sorted again using this mechanism, until the array is totally sorted.
A binary tree could be used to implement Quicksort.
This is called a divide and conquery mechanism as it runs in parallel. The Quicksort gives an average time of n log n, and this is the first sorting algorithm that did this. However, in the worst case, this could be n2 if a bad pivot (either the smallest or largest thing in the array) is chosen, although the worst case is pretty rare.
If we use a sensible pivot, we can improve the efficiency of Quicksort. A way to do this in constant time is to use the 'median-of-three' method. This is picking the first, middle and last values from the unsorted secitons and then using the median of these values as the pivot. We don't waste any comparisons here either, as the other 2 compared values can then be sorted based on their relationship to the median.
Older textbooks may give the advice to implement Quicksort using your own recursive methods, however in modern computing this is not a good idea, as optimising compilers are often better than humans and this improves the leading constant.
For small arrays, quicksort is not so good, so if the array is short (e.g., less than 10), then insertion sort should be used. Insertion sort could also be used as part of the Quicksort mechanism for the final steps.
Overall, Quicksort is a very good algorithm: Θ(n log n)
Merge sort
This is also a divide and conquer mechanism, but works in the opposite way to Quicksort. Here, an array consists of some sorted arrays with no relationship between them. The first state consists of n sorted arrays, each of length 1 and the final state consists of 1 sorted array of length n. Two sorted arrays are merged to create a larger sorted array and this is repeated until a final sorted array is reached.
This is also Θ(n log n), but it is always this complexity. Merge sort is very good for dealing with linked lists, but it does require a lot of space.
Shell's Sort
This was invented by Donald Shell, but is sometimes called just 'Shell sort'. It is a divide and conquer algorithm based on insertion sort.
Shell's sort breaks up the array into lots of little lists (e.g., each one consisting of every 4th element) and an insertion sort is done on those elements (in-place of the main list) to get a nearly ordered list which can then be efficiently sorted.
Shell used increments of 2k, where k gives us suitably small values for the initial sort, and this gives us Θ(n2) in the worst case.
However, Hibbard noticed that you didn't need to use a divide and conquer mechanism in this case, so we could use increments of 2k-1, which gives us Θ(n3/2) in the worst case and Θ(n5/4) on average.
Sedgewick recommended using overlapping for further improvements, and this gives us Θ(n4/3) in the worst case and Θ(n5/6) on average, which is very close to n log n.
Based on our original invarients, we can come up with two really bad sorting algorithms. We can either generate every possible permutation until we get the ordered one. This has complexity n!, which is ω(2n). Alternatively, you could generate every possible ordered sequence until we get one which is a permutation. This has a complexity of ∞.
However, based on these principles, we can generate a good sorting algorithm.
Bucket Sort
To do bucket sort, you need to produce a bag consisting of buckets (these buckets contain either the number of elements it represents, as in the Dutch National Flag problem, or a linked list of values, as in Quicksort). Then you produce an array that is an ordered version of the bag.
This algorithm is Θ(n), which is faster than Θ(n log n), however this is not a general sorting problem, as we must know beforehand what the possible values are. Bucket sort is therefore poor for general lists, or lists where there's a large number of keys, as it requires a lot of memory.
In conclusion, insertion sort is the best for small arrays, Shell's sort is best for medium size arrays and Quicksort (with optimisations) is best for large arrays.
Merge sort and bucket sort can also be appropriate, e.g., if there are a small amount of known values. Heap sort can also be used if the hardware is optimised for it.
Equivalence Classes
An equivalence class is like an ordering, but it works on equivalence relations.
find(x) tells us what class x is in, however instead of returning the name of the class, it returns a representative member (a typical value of the class).
union(x, a) unites the equivalence class of x with the equivalence class of a.
Forests can be used to implement this data structure. Each equivalence is represented as a tree, and the representative element is the root of the tree.
To find, you start at the tree node and go upwards until the root is hit.
To merge, just just add a pointer to point one root to the other root, making one root now a node of another tree. When deciding which direction the pointer goes, set the smaller tree to point at the larger tree. Here, smaller can mean either the fewest nodes (in which case we call the operation union by size) or lowest depth (where the operation is called union by height). However, in each case, information is required to be kept about each tree telling us either size of height.
To improve tree depth, you can use path compression. Once a find has occured, the pointer of that node can be updated to point directly at the root of the tree, and the same can be done for every node along the path to the root.
This is a trade-off - more work now for less work later.
Most implementations combine union by height with path compression, however with path compression it is difficult to keep an exact figure of height, as the height of a tree might change, but it is difficult to figure out a new tree height, so an estimate is used called 'rank', so the process is called 'union by rank with path compression'.
Amortised Analysis
Amortised analysis is finding the average running time per operation over a worst-case sequence of operations. Because we're considering a sequence, rather than a single operation, then optimisations from earlier path compressions can be considered.
For this structure, we have Ο(m log*n). The definition of log*n is log*n = 0 if log n < 1, else log*n = 1 + log*(log n). This is a very, very slow growing operation that gives us a value very close to m (linear).
We can implement this data structure using an array. If key(x) = value(x), then this is a root, otherwise parent(x) = value(x). Roots also need to hold a second value, showing the rank of the tree they represent.
Graphs
Graphs are representations of networks, relations and functions of pairs. They are made up of nodes (or vertices) and they are connected by edges (or arcs).
Graphs have various dimensions to consider, and the most important of this is directed/undirected.

Another dimension by which graphs differ are weighted/unweighted. The above graphs are unweighted.
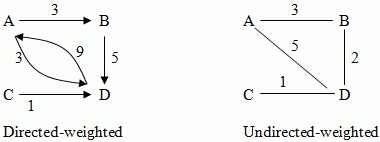
An unweighted graph can be represented as a weighted graph where the weighting is 1 is an arc exists, otherwise the weighting ∞.
In a graph, a path is a sequence of touching edges, and a cycle is a path whose start node and end node is in the same place and the path length is ≥ 1 edge. From this we can define an acyclic graph, which is a graph where there are no cycles.
Directed acyclic graphs (DAGs) are an important type of graph - forests are special types of DAGs and DAGs are very nearly forests, but they don't have the concept of a graph root.
In undirected graphs, it is easier to define a graph component. We can say that A and B is in the same component if a path exists between A and B. In directed graphs, it is harder to define what a component is, as it is not necessarily possible to get to a node from another node, but it may be possible to do the same in reverse.
See ICM for more
about strong/weak
connections in graphs
We can consider a graph to be strongly connected if, ∀ nodes A,B, A ≠ B, ∃ path A→B, B→A. For a graph to be weakly connected, direction is not considered.
The final thing to consider is whether or not the graph is sparse (has few edges) or dense (almost every node is connected with an edge).
We can have a spanning forest if every node in the graph is in a tree and connectivity between the elements is the same as the graph (all connectiong in tree = same as original graph).
Now we can consider how we would implement graphs.
Adjacancy Matrix
Each cell contains the distance between two points, e.g.,
| A | B | C | D | |
| A | 0 | 3 | 9 | ∞ |
| B | ∞ | 0 | 5 | ∞ |
| C | 3 | ∞ | 0 | ∞ |
| D | ∞ | ∞ | 1 | 0 |
This tells us (for example) that from A to C, this has weighting 9. This kind of structure has a space complexity of Θ(v2), where v is the number of vertices, but it does have a lookup complexity of Θ(1).
Adjacency List
In the real world, most graphs have a large v and a small e (number of edges), so we could construct an array of linked lists and information is stored in the same way as an adjacancy matrix, except where no arc exists then this entry does not exist in the linked list. This gives us something that looks like this:
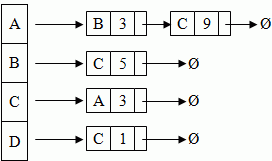
This has a space complexity of Θ(v + e), which is linear in the sum of v and e and an access complexity of Θ(e) - although this has a very small leading constant.
Spanning trees
More about spanning
tree in CLRS.
Spanning trees can be built with either depth-first (which gives us long, thin trees which can be implemented using a stack) or breadth-first (giving us short, fat trees and implemented using a queue) searches. The components in a directed graph can be considered by their connection.
Topological Sort
The input to this sort is a partial ordering (which is a DAG) and the output is a sequence representing the partial order.
To do a topological sort, you need to compute a depth-first search tree and then the reverse of the finished order is a suitable sequence.
Depth-First Search
To do a depth-first search, pick any node and follow the children until it finds a leaf (or a node where all children from that node have been visited) and put the leaf in the sequence. Repeat for each child to that node until all the children have been visited and continue with any other unvisited node.
This algorithm is non-deterministic.
There are two famous algorithms that work with graphs that we can consider. They both take a weighted, undirected graph and they output a minimal spanning tree. Both of these algorithms are greedy (one which makes the best possible step and assumes that is the correct step to take) and are dual mechanisms of each other.
Prim's Algorithm
This has the invariant that the current tree is the minimal tree for its subgraph. To implement this algorithm, you pick a node and then choose the smallest (least weighting) arc to add to the tree. You continue picking the smallest arc (that doesn't connect to an already connected node) until all arcs are picking - the chosen arc can be from anywhere in the tree.
This can be implemented using a priority queue (a heap is best) and is Θ(e log v) in the worst case.
Kruskal's Algorithm
The invariant in this algorithm is to maintain a forest of minimal trees that span the graph. The algorithm works similarly to Prim's, but you start with n trees of size 1 and then the trees are linked together using the shortest arc (where that arc doesn't link to an existing connected node) until there is only 1 tree left. This can be implemented using a priority queue and the union/find equivalence trees and is again Θ(e log v) in the worst case.
In practice, some evidence points to Kruskal's algorithm being better, but whether or not this is the case depends on the exact graph structure.
Dijkstra's Shortest Path Algorithm
This takes inputs of a directed, positive weighted graph and a distinguished node and then outputs a tree rooted at v that is the minimal of all such trees that reaches as many nodes as possible.
The algorithm works by looking at all nodes going out of a tree and adding an arc to the tree if it's the shortest route to that node.
Biconnectivity
An articulation point is a node in a connected graph with the property of removal leaving an unconnected graph. A biconnected graph is a connected (undirected) graph with no articulation points.
To find out if a graph is biconnected:
- Build a DFS tree and number the vertices by the order which they were visited in the DFS - this gives us N(v).
- Calculate L(v). This is a number representing how far we can go up the three without following the tree (i.e., using arcs that are not in the tree, but are in the graph (however this could only be done once) and following the tree downwards) L(v) = min( {N(v)} ∪ {N(w) | v → w is a backedge } ∪ {L(w) | v → w is a tree edge}) - this is calculated using a post-order traversal of the DFS tree
- The root is an articulation point if it has > 1 child, otherwise non-root node v with child w is an articulation point if L(w) ≥ N(v)
Travelling Salesman
Is there a cycle that:
- reaches all nodes
- only visits each node once
- has a distance of less than k
The famous travelling salesman is a form of this problem, where k is the minimal possible number of paths. There are no known good solutions to this, the only solutions that are currently known are to try every single cycle and see which one is the best, this has very low efficiency.
However, if we have a candidate cycle, how hard is it to check that the cycle does fulfill the criteria? It is only Θ(n) to check. This type of algorithm is an NP-hard algorithm - non-determinate and can be checked in polynomial time. We can use heuristics (approximate answers) to solve NP-hard equations.
String Searching
We have a source string and a pattern. The source may contain an instance of the pattern called the target. The question is whether or not the pattern is in the source, and if so, where in the source. We have two variables, s, the length of the source and p, the pattern length.
Naïve Approach
Break the source into arrays of length p (containing each possible combination) and do a linear search. This gives us Θ(sp) - linear in s and p.
Knuth-Morris-Pratt
See book for full description
The Knuth-Morris-Pratt method uses finite state automata for string matching.
Boyer and Moore's algorithm is an improved algorithm based on Knuth-Morris-Pratt.
Baeza-Yates and Gonnect
"A new approach to string searching"
Comm ACM vol. 35 iss. 10
pages 74-82 October 1992
- Build a table, the columns are the pattern, the rows are indexed by letters of the alphabet
- The table is enumerated such that cell is 1 if the row = column, otherwise it is 0
- For each letter in the source, put the reverse of the patern from that row for that letter, offset by the letter position of the source word
- If we get 0s in a row, we have a match
This can be implemented using shift and or at hardware level, so is very fast.
When deciding the complexity for this, we have a new variable, a, the size of the alphabet (may also be constant). This gives us Θ(s + ap), and if a and p are relatively smaller, we could consider this as just Θ(s).
The construction of the table allows a great deal of flexibility (case insensitivity, etc).
Algorithm Design Strategies
Divide and Conquer
Split the problem into two, solve it and combine answers
Greedy Strategy
Making locally optimal choices produces a globally optimal solution.
The opposite of this is a backtracking solution, keep making choices until you run into a dead end, then go back to the last choice and change it to produce an optimal solution.
Dynamic Programming
When a sub-result is needed many times, store it the first time it is calculated (memoisation).
Random Algorithms
If we use an algorithm that gives us a false positive (such as in the case of Fermat's Lesser Theorem for discovering primes), if we repeat the algorithm many times, the probability of a false positive greatly decreases (in the case of Fermat's Lesser Theorem, by trying 100 values, the chance of error reduces from 0.25 to 2-200, which is less than the probability of hardware error.
Heuristic Search Methods
There are two main types of heuristic search methods, genetic algorithms and simulated annealing. These types of algorithms search all possible answers in a semi-intelligent way. f is the function giving fitness of a value and f(s) is a measure of how good s is. We find our answer when s is fit enough.